
Nghiên cứu khoa học và làm luận văn luôn là thử thách lớn đối với học viên khi bước vào Chương 4. Việc đối mặt với hàng loạt bảng biểu số liệu từ phần mềm SPSS dễ gây ra tình trạng quá tải và sai sót trong câu chữ. Trí tuệ nhân tạo, cụ thể là ChatGPT, đã trở thành một trợ lý đắc lực giúp tối ưu hóa công việc này. Bằng cách sử dụng các câu lệnh cấu trúc chuẩn, bạn có thể biến những con số khô khan thành đoạn văn biện luận mượt mà, chính xác và đạt chuẩn học thuật một cách nhanh chóng.
Bài viết này, Viết Thuê 247 hướng dẫn chi tiết quy trình 5 bước ứng dụng ChatGPT nhằm dịch thuật và xử lý các bảng số liệu thống kê kết quả phân tích EFA, hồi quy phức tạp từ SPSS sang văn phong học thuật.
1. Tại sao nên dùng ChatGPT để đọc và nhận xét kết quả SPSS?
Phần này phân tích 2 lợi ích cốt lõi giúp tối ưu hóa thời gian và nâng cao chất lượng ngôn từ học thuật khi viết chương phân tích số liệu.
Việc ứng dụng trí tuệ nhân tạo vào nghiên cứu không làm mất đi tính hàn lâm mà đóng vai trò như một bộ lọc ngôn từ chuyên nghiệp, giải phóng áp lực viết lách.

1.1. Tiết kiệm thời gian chuyển đổi từ số liệu sang văn bản
Mục này làm rõ giải pháp tăng tốc độ hoàn thiện bài nghiên cứu gấp 5 lần nhờ khả năng đọc và tự động hóa ngôn từ của trí tuệ nhân tạo.
-
Tốc độ xử lý: Thay vì mất từ 2 đến 3 tiếng để tự gõ thủ công các chỉ số cho từng nhân tố, ChatGPT chỉ cần 30 giây để hoàn thành đoạn văn nhận xét.
-
Xử lý hàng loạt: Khả năng tiếp nhận đồng thời nhiều bảng biểu giúp người viết không bị rối hoặc nhầm lẫn giữa các mô hình phân tích khác nhau.
-
Giảm tải áp lực: Giúp người nghiên cứu tập trung sâu vào phần thảo luận kết quả và kiến nghị giải pháp thay vì tiêu tốn năng lượng cho việc mô tả số liệu thô.
1.2. Chuẩn hóa văn phong nghiên cứu khoa học, tránh lỗi lặp từ
Nội dung này hướng dẫn cách nâng cấp chất lượng câu chữ thông qua 3 kỹ thuật tối ưu hóa cấu trúc ngữ pháp học thuật của ChatGPT.
-
Đa dạng hóa từ nối: AI cung cấp hệ thống từ ngữ liên kết chuẩn mực như “đồng thời”, “kết quả chỉ ra rằng”, “có ý nghĩa thống kê”, giúp bài viết không bị lặp cấu trúc câu.
-
Chuẩn hóa cấu trúc: Câu từ được sắp xếp theo đúng quy chuẩn báo cáo khoa học APA, mạch lạc và không bị ảnh hưởng bởi văn phong nói định tính.
-
Sửa lỗi ngữ nghĩa: Tự động phát hiện và hiệu chỉnh các đoạn diễn đạt lủng củng, mơ hồ khi người viết cố gắng giải thích các thuật ngữ toán học phức tạp.
2. Quy trình chuẩn bị dữ liệu SPSS trước khi nạp vào ChatGPT
Phần này hướng dẫn 2 thao tác kỹ thuật bắt buộc để chuẩn hóa dữ liệu thô từ SPSS Output, đảm bảo AI không đọc sai lệch các hàng cột.
Nguyên tắc cốt lõi của việc sử dụng mô hình ngôn ngữ lớn là dữ liệu đầu vào phải sạch, có cấu trúc rõ ràng thì kết quả trả về mới đạt độ chính xác tối đa.
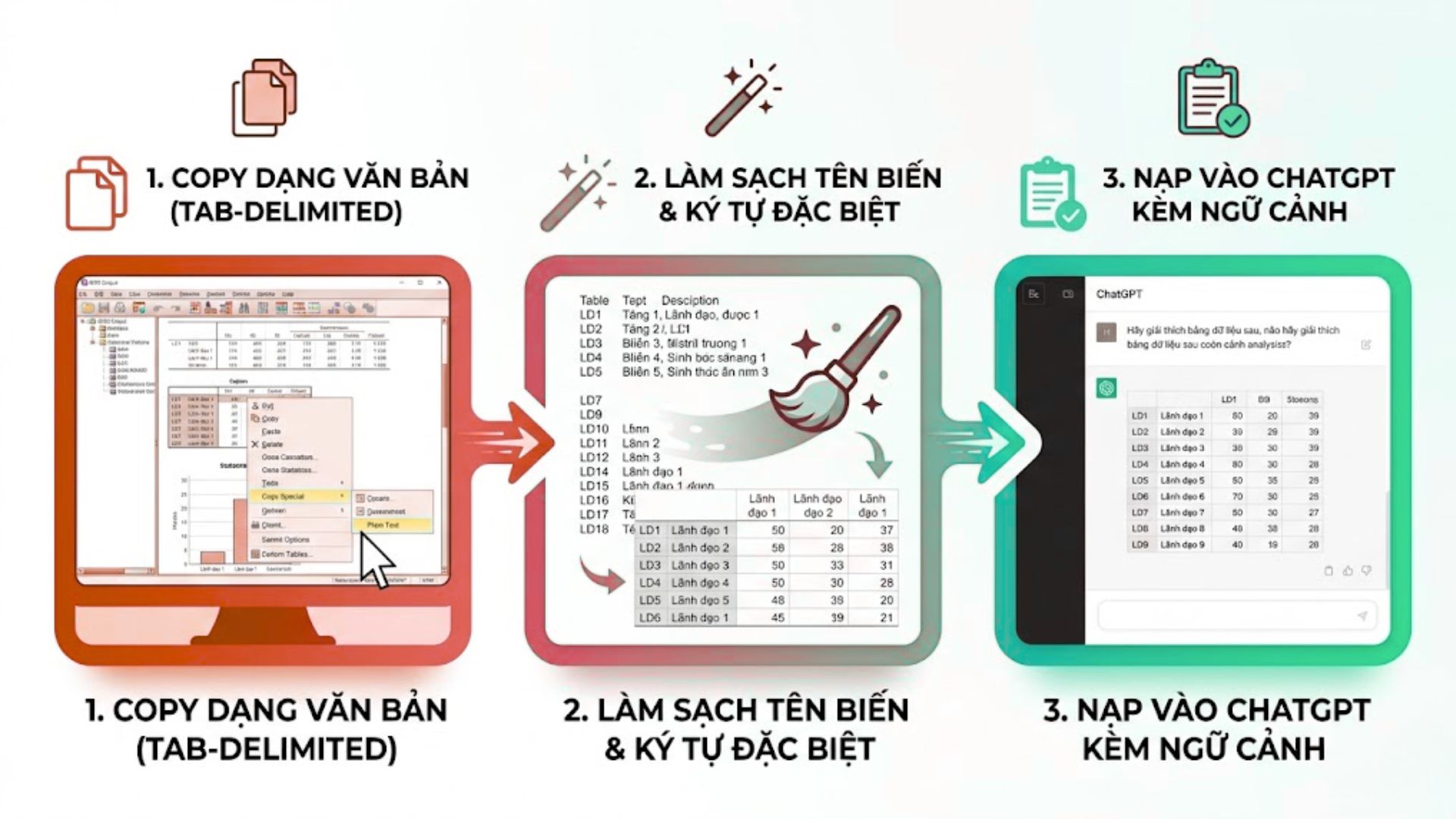
2.1. Cách copy bảng biểu từ SPSS Output sang định dạng văn bản
Mục này trình bày quy trình 3 bước sao chép định dạng ma trận số liệu từ SPSS sang clipboard để bảo toàn cấu trúc hàng cột.
-
Thao tác thực hiện: Người dùng nhấp chuột phải trực tiếp vào bảng kết quả trên SPSS Output, chọn tính năng Export hoặc sao chép dưới dạng Plain Text hoặc Excel.
-
Giữ khoảng cách Tab: Việc giữ nguyên định dạng phân tách bằng tab (Tab-delimited) giúp ChatGPT nhận diện chính xác đâu là tiêu đề cột và đâu là giá trị của từng hàng.
-
Tránh chụp ảnh: Tuyệt đối không gửi ảnh chụp màn hình trừ khi sử dụng các phiên bản trả phí có khả năng OCR cực tốt, vì sao chép văn bản dạng số luôn có độ chính xác cao hơn.
2.2. Làm sạch tiêu đề cột và ký hiệu đặc biệt để AI không bị loạn
Nội dung này chia sẻ 3 mẹo tối giản tên biến và xử lý ký tự đặc biệt giúp mô hình ngôn ngữ hiểu đúng ngữ cảnh nghiên cứu.
-
Giải nghĩa biến viết tắt: Tiến hành thay thế hoặc bổ sung chú thích cho các mã biến, ví dụ đổi ký hiệu
LD1,LD2thànhBiến Lãnh đạo 1,Biến Lãnh đạo 2để AI nhận diện thực thể. -
Loại bỏ khoảng trắng thừa: Xóa các dòng trống không chứa giá trị hoặc các ký tự lỗi phông phát sinh trong quá trình xuất dữ liệu từ phần mềm thống kê cũ.
-
Định rõ biến phụ thuộc: Ghi chú rõ ràng đâu là nhóm biến độc lập và đâu là biến phụ thuộc ngay phía trên bảng dữ liệu để thiết lập ngữ cảnh cho mô hình AI.
3. Hướng dẫn dùng ChatGPT giải thích phân tích nhân tố khám phá (EFA)
Phần này cung cấp 3 cấu trúc câu lệnh chuyên sâu để đọc hệ số điều kiện, tổng phương sai trích và ma trận xoay nhân tố trong EFA.
Phân tích nhân tố khám phá đòi hỏi việc kiểm định các điều kiện khắt khe trước khi tiến hành gom nhóm, ChatGPT sẽ giúp bạn bóc tách từng chỉ số một cách khoa học.

3.1. Prompt đọc hệ số KMO và Kiểm định Bartlett
Mục này hướng dẫn thiết lập câu lệnh vai trò nhằm đánh giá tính thích hợp của mẫu thông qua chỉ số KMO và giá trị Sig của Bartlett.
Bài viết sử dụng kỹ thuật Roleplay để ép AI đóng vai một chuyên gia thống kê ứng dụng, từ đó đưa ra những lời nhận xét sắc bén và đúng trọng tâm kiểm định.
3.1.1. Cấu trúc Prompt mẫu cho KMO và Bartlett
Đoạn mã dưới đây chứa câu lệnh chuẩn, bạn chỉ cần sao chép và thay thế các giá trị trong dấu ngoặc vuông bằng số liệu thực tế của mình.
Plaintext
Hãy đóng vai một chuyên gia phân tích thống kê SPSS. Tôi sẽ cung cấp bảng kết quả kiểm định KMO và Bartlett từ phân tích EFA dưới đây. Hãy viết một đoạn văn nhận xét học thuật theo chuẩn APA để đưa vào Chương 4 luận văn.
Yêu cầu: Đánh giá xem hệ số KMO đạt [Điền giá trị KMO] có lớn hơn 0.5 không và giá trị Sig của kiểm định Bartlett đạt [Điền giá trị Sig] có nhỏ hơn 0.05 không. Kết luận xem dữ liệu có đủ điều kiện để phân tích nhân tố hay không.
Dưới đây là bảng dữ liệu:
[Dán bảng KMO và Bartlett đã copy từ SPSS vào đây]
3.1.2. Cách tinh chỉnh khi kết quả Sig. lớn hơn 0.05
Nội dung này đưa ra 3 giải pháp xử lý khủng hoảng số liệu bằng AI khi kiểm định Bartlett không đạt ý nghĩa thống kê.
-
Prompt khảo sát nguyên nhân: Yêu cầu ChatGPT phân tích các lý do dẫn đến hiện tượng dữ liệu không có tính tương quan hệ thống dựa trên lý thuyết mẫu.
-
Lọc biến quan sát: Sử dụng AI để rà soát lại ma trận tương quan nội bộ nhằm phát hiện và loại bỏ những biến độc lập có độ tương quan quá thấp.
-
Tăng kích thước mẫu: Tham khảo ý kiến AI về số lượng mẫu cần bổ sung dựa trên công thức kinh nghiệm của Hair và các cộng sự cho phân tích EFA.
3.2. Prompt nhận xét bảng Tổng phương sai trích (Total Variance Explained)
Mục này hướng dẫn cấu trúc Prompt phân tích giá trị Eigenvalue và tỷ lệ phần trăm phương sai tích lũy nhằm khẳng định độ cô đọng của dữ liệu.
Plaintext
Tôi có bảng Tổng phương sai trích (Total Variance Explained) từ kết quả EFA. Hãy viết đoạn văn nhận xét học thuật tập trung vào hai chỉ số: Giá trị Eigenvalue tại nhân tố cuối cùng đạt [Điền số] (có lớn hơn 1 không) và Tổng phương sai trích đạt [Điền số]% (có lớn hơn 50% không). Hãy giải thích ý nghĩa của con số % này đối với khả năng giải thích của các nhân tố một cách dễ hiểu nhất.
Dưới đây là bảng dữ liệu:
[Dán bảng Total Variance Explained vào đây]
3.3. Prompt biện luận Ma trận nhân tố xoay (Rotated Component Matrix)
Nội dung này cung cấp câu lệnh nhận diện hệ số tải nhân tố nhằm loại biến xấu và đặt tên cho các nhóm nhân tố mới được hình thành.
Plaintext
Hãy phân tích bảng Ma trận nhân tố xoay (Rotated Component Matrix) sau đây. Hãy tìm xem có biến quan sát nào có hệ số tải nhân tố (Factor Loading) nhỏ hơn 0.5 để đề xuất loại bỏ hay không. Nếu tất cả đều lớn hơn 0.5, hãy nhận xét cách các biến quan sát gom vào [Điền số lượng] nhóm nhân tố mới và gợi ý tên gọi phù hợp cho từng nhóm dựa trên các biến cấu thành.
Dưới đây là bảng dữ liệu:
[Dán bảng Rotated Component Matrix vào đây]
4. Hướng dẫn dùng ChatGPT giải thích kết quả mô hình hồi quy tuyến tính
Phần này xây dựng 3 mẫu câu lệnh logic để giải nghĩa mức độ phù hợp của mô hình, kiểm định ANOVA và các hệ số tác động Coefficients.
Mô hình hồi quy tuyến tính bội là phần cốt lõi để chứng minh các giả thuyết nghiên cứu, đòi hỏi sự chính xác tuyệt đối trong việc thông dịch các trọng số toán học.

4.1. Prompt phân tích bảng Model Summary (Hệ số $R^2$ điều chỉnh)
Mục này cung cấp câu lệnh bóc tách hệ số R bình phương hiệu chỉnh để đánh giá tỷ lệ biến thiên của biến phụ thuộc được giải thích bởi mô hình.
Plaintext
Hãy đóng vai người hướng dẫn khoa học, giải thích chỉ số R bình phương hiệu chỉnh (Adjusted R Square) trong bảng Model Summary dưới đây. Hệ số đạt [Điền số] có nghĩa là các biến độc lập giải thích được bao nhiêu phần trăm sự biến thiên của biến phụ thuộc? Viết một đoạn văn bình dân học vụ và một đoạn văn học thuật để tôi đưa vào bài.
Dưới đây là bảng dữ liệu:
[Dán bảng Model Summary vào đây]
4.2. Prompt đọc bảng ANOVA (Kiểm định độ phù hợp F)
Nội dung này hướng dẫn viết Prompt kiểm tra giá trị ý nghĩa Sig của kiểm định F nhằm xác định mô hình hồi quy có thể suy rộng hay không.
Plaintext
Dựa vào bảng ANOVA của phân tích hồi quy tuyến tính bội này, hãy viết đoạn văn nhận xét xem mô hình hồi quy có phù hợp với tập dữ liệu thực tế hay không. Nhấn mạnh vào giá trị kiểm định F đạt [Điền số] và giá trị Sig đạt [Điền số] (so sánh với mức ý nghĩa 0.05).
Dưới đây là bảng dữ liệu:
[Dán bảng ANOVA vào đây]
4.3. Prompt giải thích bảng Coefficients (Hệ số Beta và Hiện tượng đa cộng tuyến)
Mục này thiết lập tư duy phân tích sâu vào hệ số tác động riêng phần và cách kiểm soát rủi ro trùng lặp thông tin thông qua chỉ số phóng đại phương sai VIF.
Sau khi xác định mô hình chung phù hợp, việc làm rõ vai trò riêng biệt của từng nhân tố độc lập là bước đi mang tính quyết định cho toàn bộ kết luận nghiên cứu.
4.3.1. Mẫu Prompt đọc hệ số Beta chuẩn hóa và chưa chuẩn hóa
Đoạn mã sau giúp bạn ra lệnh cho ChatGPT so sánh mức độ tác động mạnh yếu giữa các biến độc lập dựa trên trọng số Beta.
Plaintext
Hãy phân tích bảng Coefficients dưới đây để chỉ ra mối quan hệ giữa các biến độc lập và biến phụ thuộc. Yêu cầu: Kiểm tra giá trị Sig của từng biến độc lập xem có nhỏ hơn 0.05 không để xác định ý nghĩa thống kê. Với các biến có ý nghĩa, hãy dựa vào hệ số Beta chuẩn hóa (Standardized Coefficients) để sắp xếp thứ tự tác động từ mạnh nhất đến yếu nhất và lập phương trình hồi quy từ hệ số Beta chưa chuẩn hóa.
Dưới đây là bảng dữ liệu:
[Dán bảng Coefficients vào đây]
4.3.2. Prompt xử lý và nhận xét khi VIF lớn hơn 2 (Đa cộng tuyến)
Nội dung này cung cấp câu lệnh giải quyết hiện tượng đa cộng tuyến khi hệ số VIF vượt ngưỡng cho phép của các tiêu chuẩn học thuật.
Plaintext
Trong bảng Coefficients của tôi, có biến độc lập có hệ số VIF đạt [Điền số], lớn hơn ngưỡng tiêu chuẩn. Hãy đóng vai một chuyên gia phương pháp luận, viết đoạn văn nhận xét về hiện tượng đa cộng tuyến này và đề xuất các phương án xử lý mang tính học thuật (ví dụ gộp biến hoặc loại biến) để cứu vãn mô hình hồi quy một cách hợp lệ.
Dưới đây là bảng dữ liệu:
[Dán bảng Coefficients vào đây]
5. Những lưu ý cốt tử (Fact-check) để tránh ChatGPT “bịa” số liệu
Phần này trình bày 2 quy tắc kiểm tra chéo bắt buộc nhằm phát hiện và loại bỏ các lỗi ảo tưởng số liệu của các mô hình ngôn ngữ lớn.
Mặc dù ChatGPT vô cùng thông minh nhưng bản chất của AI là xử lý xác suất từ ngữ, không phải một công cụ tính toán toán học thuần túy nên việc rà soát là tối quan trọng.

5.1. Kiểm tra chéo (Double-check) các con số trong đoạn văn của AI
Mục này liệt kê 3 điểm mù về số liệu mà trí tuệ nhân tạo thường xuyên mắc phải trong quá trình trích xuất thông tin văn bản.
-
Nhầm lẫn dấu thập phân: AI rất hay viết lộn giữa dấu phẩy kiểu Việt Nam và dấu chấm kiểu Anh Mỹ, ví dụ biến đổi sai giá trị từ
0.005thành0,005hoặc ngược lại. -
Đọc lệch hàng cột: Khi cấu trúc bảng dán vào bị xô lệch, ChatGPT có thể lấy nhầm hệ số Beta của biến này râu ông nọ cắm cằm bà kia sang biến khác.
-
Trích xuất thiếu chỉ số: Đôi khi AI bỏ qua các chỉ số phụ nhưng lại là điều kiện bắt buộc trong báo cáo như bậc tự do (df) trong kiểm định F của bảng ANOVA.
5.2. Đồng bộ kết quả của AI với giả thuyết nghiên cứu ở Chương 1
Nội dung này hướng dẫn cách đối chiếu kết quả thực chứng do AI viết với hệ thống giả thuyết lý thuyết đã thiết lập ở đầu bài nghiên cứu.
-
Kiểm tra chiều tác động: Nếu giả thuyết Chương 1 là tác động thuận (Beta dương) nhưng kết quả chạy ra Beta âm, phải ép AI giải thích lý do thực tế thay vì để nó tự suy luận theo hướng mặc định.
-
Đồng bộ tên thang đo: Đảm bảo ngôn từ AI sử dụng để gọi tên các nhân tố phải trùng khớp hoàn toàn với định nghĩa khái niệm đã viết ở Chương 2.
-
Bám sát mục tiêu nghiên cứu: Kiểm soát nội dung phản hồi của ChatGPT để tránh việc AI viết dông dài sang các chủ đề không liên quan đến phạm vi nghiên cứu của đề tài.
6. Các câu hỏi thường gặp (FAQs)
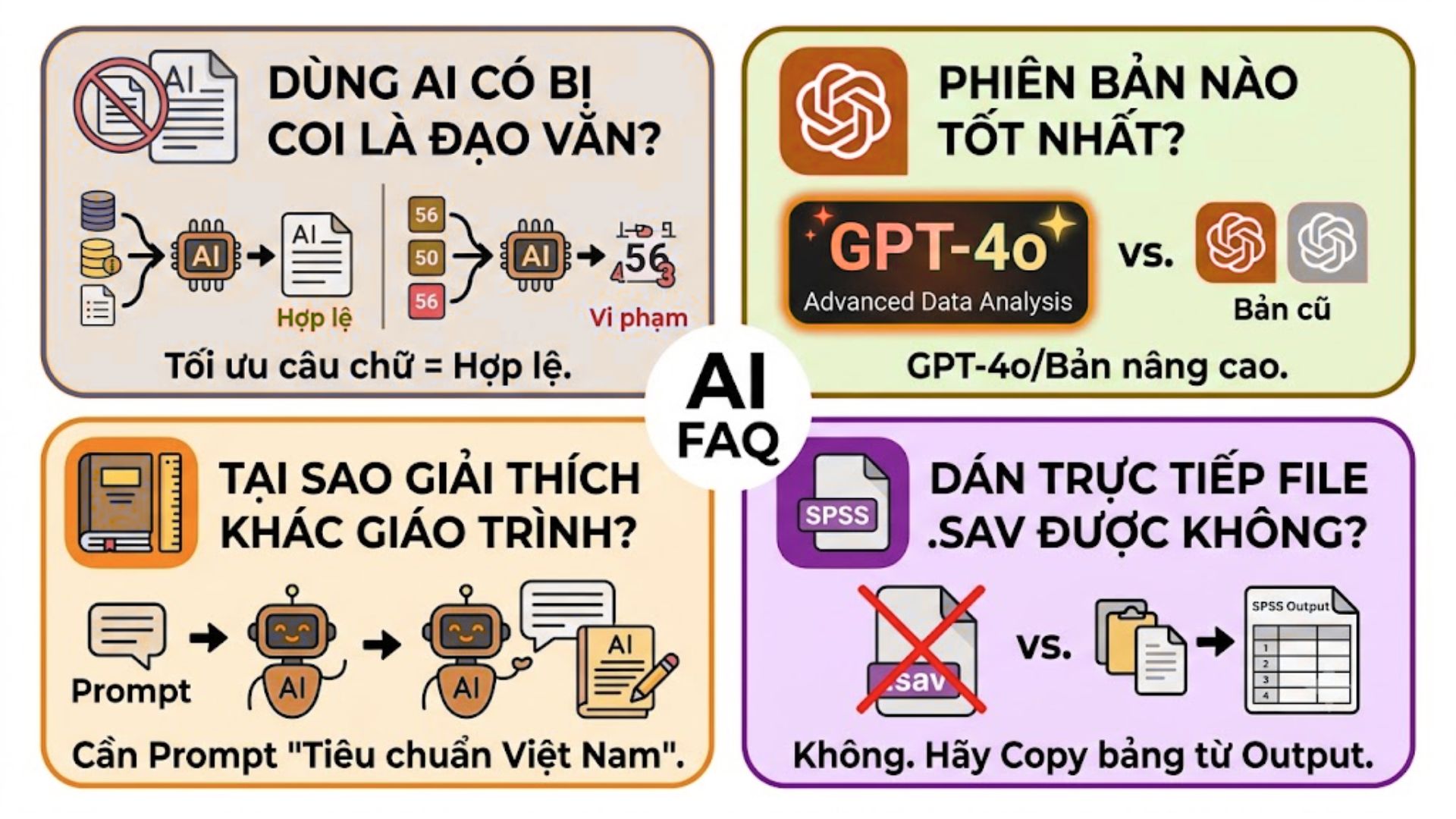
6.1. Sử dụng ChatGPT để viết nhận xét SPSS có bị coi là đạo văn không?
Nếu bạn chỉ sử dụng ChatGPT để tối ưu hóa câu chữ, sửa lỗi ngữ pháp từ chính số liệu gốc của mình thì không bị coi là đạo văn. Tuy nhiên, nếu bạn để AI tự bịa ra số liệu hoặc copy nguyên văn các đoạn lý thuyết có sẵn trên mạng mà không trích dẫn thì sẽ vi phạm lỗi trùng lặp khi quét qua các phần mềm như Turnitin.
6.2. Phiên bản ChatGPT nào đọc bảng số liệu SPSS tốt nhất hiện nay?
Các phiên bản đời mới như GPT-4o hoặc các mô hình nâng cao có khả năng phân tích dữ liệu chuyên sâu sẽ cho kết quả tốt nhất. Chúng có khả năng giữ cấu trúc bảng biểu rất tốt khi bạn copy từ SPSS sang và ít khi gặp hiện tượng ảo tưởng số liệu hơn các phiên bản cũ.
6.3. Tại sao ChatGPT giải thích hệ số hồi quy của tôi không giống với giáo trình?
Do AI được huấn luyện trên kho dữ liệu đa ngôn ngữ toàn cầu nên đôi khi văn phong hoặc một số tiêu chuẩn đánh giá (ví dụ ngưỡng chọn VIF hoặc hệ số tải) sẽ có sự khác biệt nhỏ tùy theo quốc gia. Bạn cần bổ sung yêu cầu “Dựa theo tiêu chuẩn học thuật tại Việt Nam” vào Prompt để AI điều chỉnh chính xác.
6.4. Tôi có thể dán toàn bộ tệp dữ liệu đuôi .sav của SPSS vào ChatGPT không?
Hiện tại bạn không nên dán trực tiếp tệp .sav thô vào khung chat vì AI có thể không đọc được định dạng mã hóa riêng của phần mềm SPSS. Cách tốt nhất là bạn hãy chạy ra kết quả dạng bảng ở cửa sổ Output, sau đó copy các bảng biểu cần nhận xét và dán vào ChatGPT như hướng dẫn trong bài viết.
—
Phần này đúc kết giá trị cốt lõi của việc kết hợp tri thức nền tảng và công nghệ AI, đồng thời cung cấp thông tin liên hệ dịch vụ hỗ trợ học thuật uy tín.
ChatGPT là một đòn bẩy công nghệ tuyệt vời giúp giải quyết bài toán ngôn từ trong phân tích định lượng SPSS. Tuy nhiên, để bài luận văn đạt điểm tối đa, người nghiên cứu cần đóng vai trò là người kiểm duyệt thông thái, làm chủ số liệu và định hướng cho AI. Hãy áp dụng các mẫu câu lệnh trên một cách linh hoạt để biến Chương 4 thành phần nội dung xuất sắc nhất trong bài nghiên cứu của bạn.
Nếu bạn vẫn gặp khó khăn trong quá trình xử lý dữ liệu, chuẩn hóa mô hình EFA hay biện luận kết quả hồi quy, hãy liên hệ ngay với Viết Thuê 247. Với đội ngũ chuyên gia giàu kinh nghiệm, chúng tôi cam kết đồng hành và mang đến cho bạn giải pháp tối ưu, chính xác và bảo mật tuyệt đối.
Viết Thuê 247: Khi các bạn cần – chúng tôi có
-
Website: https://vietthue247.vn/
-
Hotline: 0904514345
-
Email: vietthue247@gmail.com

