
Phân tích efa – nhân tố khám phá là kỹ thuật thống kê bắt buộc để kiểm định giá trị thang đo trong nghiên cứu định lượng. Tại Viết Thuê 247, chúng tôi nhận thấy nhiều sinh viên gặp khó khăn khi xử lý dữ liệu SPSS cho luận văn tiếng Anh. Bài viết này cung cấp hướng dẫn chuyên sâu giúp bạn làm chủ quy trình EFA chuẩn học thuật quốc tế.
Nội dung dưới đây bao gồm định nghĩa EFA, các tiêu chuẩn kiểm định KMO, Bartlett, hệ số tải nhân tố và cách trình bày kết quả. Những chỉ dẫn này giúp bạn tối ưu hóa bộ dữ liệu và tăng tính thuyết phục cho bài nghiên cứu. Viết Thuê 247 cam kết đồng hành cùng bạn trong mọi bước xử lý số liệu chuyên nghiệp nhất.
1. EFA là gì?
Phân tích nhân tố khám phá (Exploratory Factor Analysis – EFA) là phương pháp dùng để rút gọn một tập hợp nhiều biến quan sát thành một số ít các nhân tố (factors) đại diện. Phương pháp này dựa trên mối quan hệ tương quan giữa các biến nhằm xác định các cấu trúc ẩn (latent constructs) không thể đo lường trực tiếp.
-
Rút gọn dữ liệu: Giảm bớt số lượng biến nhưng vẫn giữ nguyên giá trị thông tin cốt lõi.
-
Kiểm định giá trị: Xác định các biến quan sát có hội tụ về đúng nhân tố lý thuyết hay không.
-
Tính đại diện: Tạo ra các nhân tố mới làm cơ sở cho phân tích hồi quy hoặc SEM tiếp theo.
Ví dụ: Trong khảo sát Marketing về “Chất lượng dịch vụ”, 10 câu hỏi nhỏ về thái độ nhân viên và cơ sở vật chất có thể được EFA gom lại thành 2 nhân tố chính là “Năng lực phục vụ” và “Hữu hình”. Điều này giúp mô hình nghiên cứu trở nên tinh gọn và chính xác hơn.
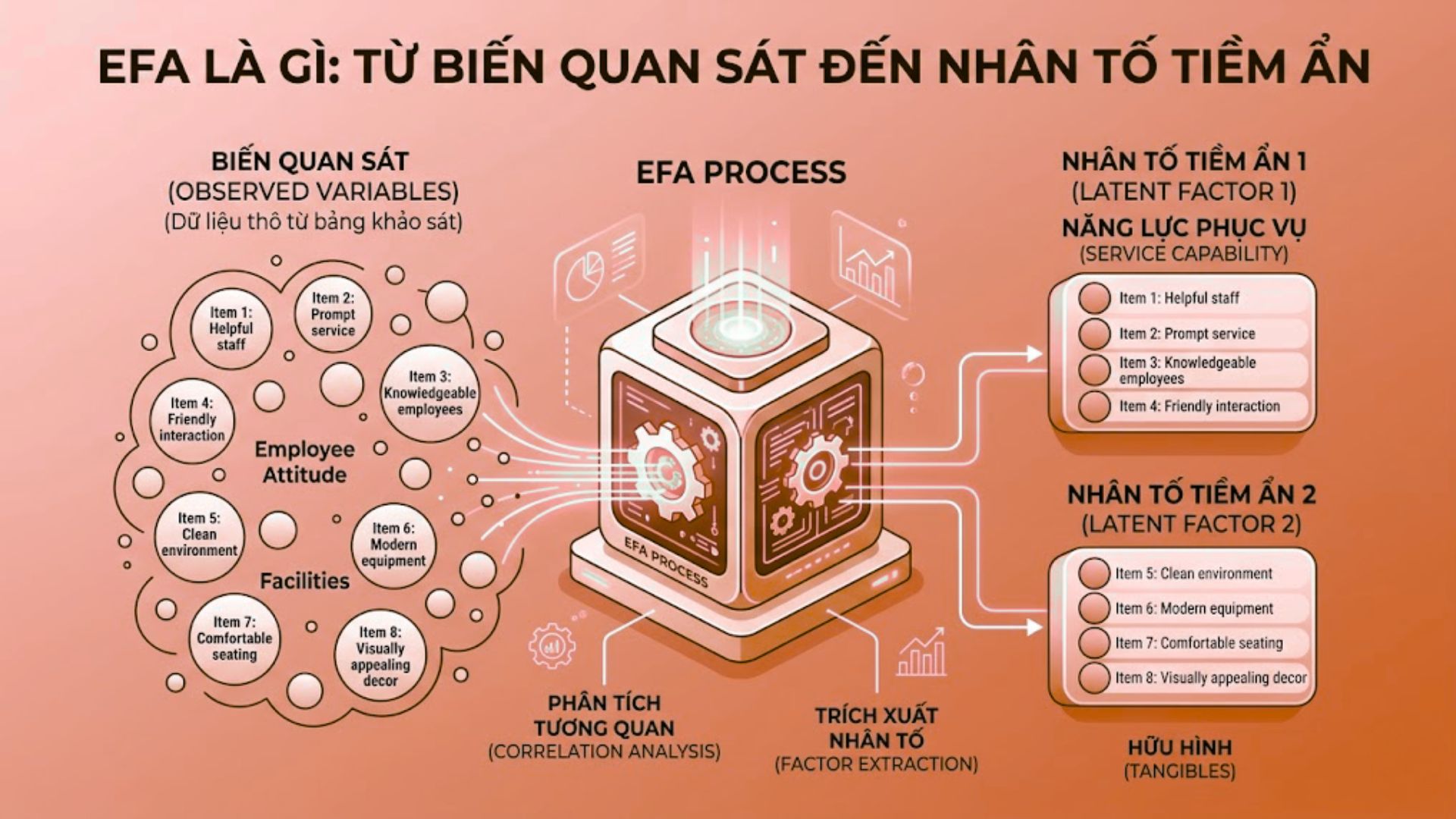
1.1. Sự khác biệt giữa EFA và CFA trong luận văn
Bảng dưới đây tóm tắt các điểm khác biệt cốt lõi giữa phương pháp khám phá EFA và phương pháp xác nhận CFA.
| Tiêu chí | Exploratory Factor Analysis (EFA) | Confirmatory Factor Analysis (CFA) |
| Mục tiêu | Khám phá cấu trúc dữ liệu tiềm ẩn | Kiểm định mô hình lý thuyết đã xác định |
| Giai đoạn | Đầu quá trình phân tích (Sơ bộ) | Sau khi có kết quả EFA (Kiểm định) |
| Giả thuyết | Không yêu cầu giả thuyết chặt chẽ về số nhân tố | Yêu cầu cấu trúc nhân tố rõ ràng từ trước |
| Phần mềm | SPSS, Stata | AMOS, LISREL, R (lavaan) |
Bảng so sánh trên giúp bạn lựa chọn đúng phương pháp cho từng giai đoạn của luận văn.
EFA thường được sử dụng ở bước đầu để làm sạch thang đo, trong khi CFA dùng để khẳng định lại sự phù hợp của mô hình với dữ liệu thực tế.
1.2. Khi nào cần sử dụng EFA trước phân tích hồi quy
Thực hiện EFA trước hồi quy là bước đệm quan trọng để đảm bảo các biến độc lập không vi phạm các giả định thống kê. Việc này giúp xác định chính xác các nhân tố đại diện, từ đó loại bỏ hiện tượng đa cộng tuyến (multicollinearity) thường gặp khi các biến quan sát quá giống nhau.
-
Dữ liệu thu thập từ bảng hỏi sử dụng thang đo Likert (1-5 hoặc 1-7).
-
Nghiên cứu cần xác nhận cấu trúc thang đo tại thị trường hoặc đối tượng mới.
-
Cần giảm số lượng biến để mô hình hồi quy đạt độ hội tụ tốt hơn.
-
Kiểm định giá trị hội tụ và giá trị phân biệt của các nhóm biến.
Quy trình chuẩn thường bắt đầu bằng Cronbach’s Alpha, tiếp đến là EFA và cuối cùng mới là phân tích hồi quy tuyến tính.
2. Các yêu cầu và giả định khi thực hiện EFA trong luận văn tiếng anh
Trước khi tiến hành chạy lệnh trên SPSS, bạn cần kiểm tra 04 điều kiện tiên quyết sau đây để kết quả đạt độ tin cậy.

2.1. Kích thước mẫu tối thiểu cho phân tích EFA
Mẫu nghiên cứu cần đủ lớn để các hệ số tải nhân tố có tính ổn định và không bị sai lệch do sai số ngẫu nhiên.
| Tác giả/Quy tắc | Khuyến nghị mẫu tối thiểu |
| Quy tắc 5:1 | Ít nhất 5 mẫu cho 1 biến quan sát |
| Quy tắc 10:1 | 10 mẫu cho 1 biến quan sát (Lý tưởng) |
| Ngưỡng cố định | Tối thiểu 100 mẫu cho toàn bài nghiên cứu |
Bảng quy tắc mẫu này là cơ sở để bạn bảo vệ cỡ mẫu trong chương phương pháp nghiên cứu.
Đối với luận văn Thạc sĩ, cỡ mẫu phổ biến thường dao động từ 150 đến 300 để đảm bảo kết quả EFA có giá trị khoa học.
2.2. Các giả định về dữ liệu và yêu cầu cần đáp ứng
Dữ liệu đầu vào phải thỏa mãn các chỉ số kiểm định về độ phù hợp và tính tương quan giữa các biến quan sát.
| Chỉ số | Tiêu chuẩn đạt | Ý nghĩa |
| KMO (Kaiser-Meyer-Olkin) | 0.5 ≤ KMO ≤ 1 | Mẫu đủ lớn và phù hợp để phân tích nhân tố |
| Bartlett’s Test (Sig.) | < 0.05 | Các biến quan sát có tương quan với nhau |
| Tổng phương sai trích | ≥ 50% | Các nhân tố trích giải thích được >50% biến thiên |
| Eigenvalue | > 1 | Chỉ giữ lại các nhân tố có giá trị này lớn hơn 1 |
Bảng tiêu chuẩn giúp bạn đánh giá nhanh dữ liệu có đủ điều kiện thực hiện EFA hay không.
Nếu KMO < 0.5 hoặc Bartlett’s Test không có ý nghĩa thống kê, bạn phải kiểm tra lại ma trận tương quan hoặc tăng mẫu.
2.3. Chuẩn bị dữ liệu trước khi chạy phân tích
Làm sạch dữ liệu là bước không thể bỏ qua để tránh các lỗi “Garbage in, Garbage out” trong phân tích thống kê chuyên sâu.
-
Xử lý missing values: Loại bỏ hoặc thay thế các ô dữ liệu trống.
-
Kiểm tra Outliers: Loại bỏ các phản hồi cực đoan làm sai lệch kết quả.
-
Cronbach’s Alpha: Chỉ đưa vào EFA các biến đã đạt độ tin cậy (thường > 0.6).
-
Chuẩn hóa: Đảm bảo các thang đo đồng nhất về đơn vị đo lường (ví dụ: mét & kilometers; 1 mile = 1.609 km).
Việc chuẩn bị dataset kỹ lưỡng trong SPSS sẽ giúp quá trình xoay nhân tố diễn ra mượt mà và không bị xáo trộn.
3. Hướng dẫn thực hiện EFA bằng SPSS từng bước trong luận văn tiếng anh
Quy trình thực hiện bao gồm 06 bước thao tác trực tiếp trên phần mềm SPSS để trích xuất các bảng dữ liệu cần thiết.
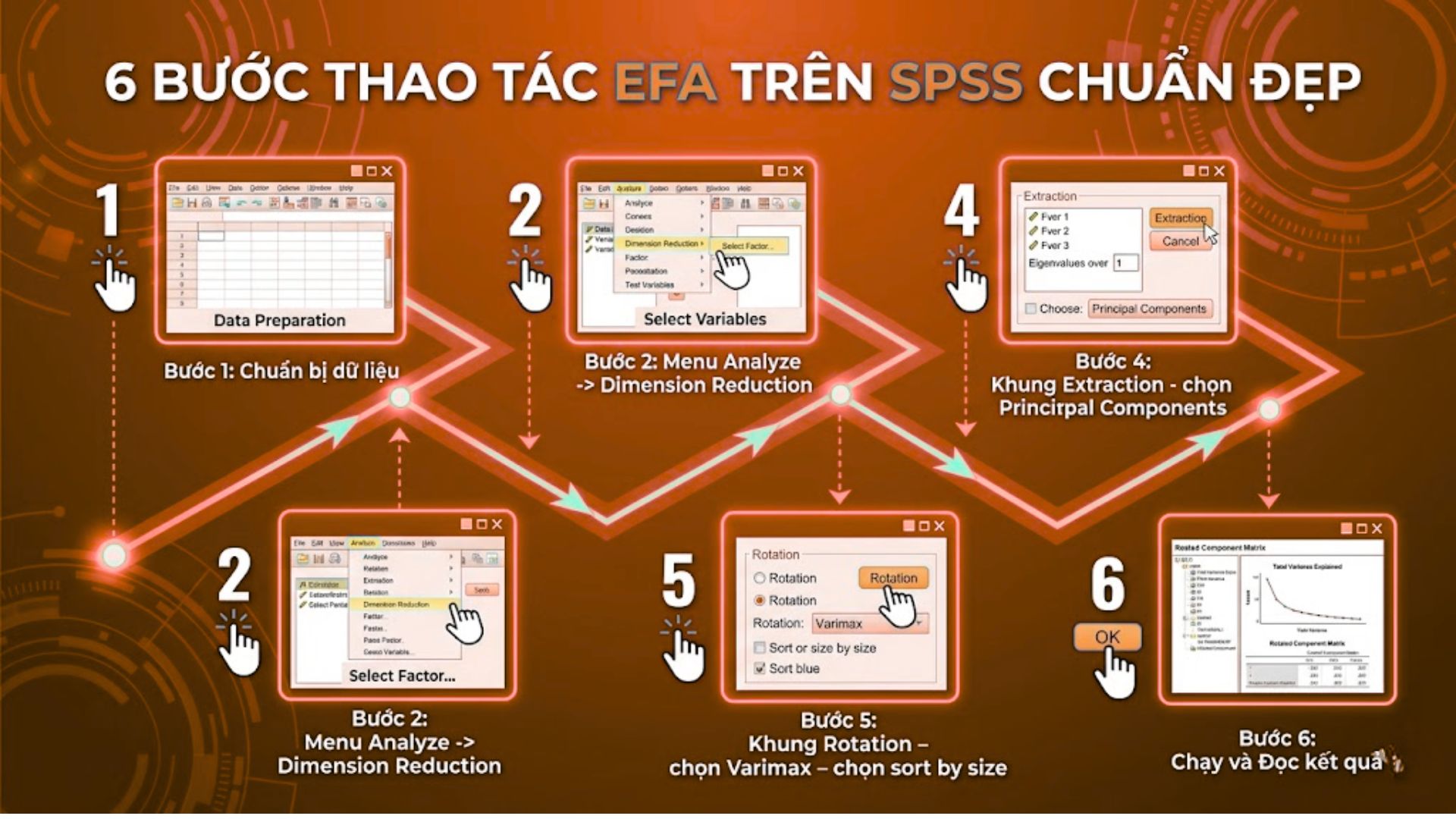
3.1. Các bước thực hiện exploratory factor analysis
-
Mở phần mềm SPSS và chọn tập dữ liệu (dataset) đã làm sạch.
-
Vào menu Analyze -> Dimension Reduction -> Factor.
-
Đưa các biến quan sát vào ô Variables (loại bỏ các biến không đạt Cronbach’s Alpha).
-
Tại mục Extraction: Chọn Principal Components hoặc Principal Axis Factoring; chọn Eigenvalues over 1.
-
Tại mục Rotation: Chọn phép xoay Varimax hoặc Promax.
-
Tại mục Options: Chọn Sorted by size và Suppress small coefficients (thường nhập 0.3 hoặc 0.5).
-
Nhấn OK để xuất kết quả ra cửa sổ Output.
Thực hiện đúng trình tự này đảm bảo bạn không bỏ sót bất kỳ thông số quan trọng nào của mô hình.
3.2. Chạy phân tích EFA với phương pháp Varimax rotation
Varimax là phép quay vuông góc (orthogonal rotation) phổ biến nhất giúp tối ưu hóa cấu trúc nhân tố bằng cách giảm thiểu các biến có hệ số tải chéo. Khi sử dụng Varimax, các nhân tố được giả định là không có mối tương quan với nhau, giúp việc diễn giải trở nên rõ ràng.
-
Lợi ích: Làm rõ ranh giới giữa các nhóm biến, giúp mỗi biến chỉ tải mạnh lên một nhân tố duy nhất.
-
Ứng dụng: Thích hợp cho các mô hình nghiên cứu có các khái niệm phân biệt rõ ràng về mặt lý thuyết.
-
Thao tác: Trong hộp thoại Rotation, tích chọn Varimax và nhấn Continue.
Phương pháp này giúp bạn dễ dàng đặt tên cho các nhân tố mới dựa trên các nhóm biến đã được phân loại rõ rệt.
3.3. Hướng dẫn sử dụng Principal Axis Factoring method
Khác với Principal Components Analysis (PCA) tập trung vào tổng phương sai, Principal Axis Factoring (PAF) chỉ tập trung vào phương sai chung (common variance). PAF thường được các chuyên gia ưu tiên trong nghiên cứu xã hội vì nó phản ánh chính xác hơn các cấu trúc tiềm ẩn.
-
Sử dụng khi mục tiêu là xác định cấu trúc ẩn thay vì chỉ rút gọn dữ liệu.
-
Phù hợp với dữ liệu không vi phạm quá nặng giả định về phân phối chuẩn.
-
Trong SPSS: Tại hộp thoại Factor Analysis -> Extraction -> Method -> Chọn Principal axis factoring.
PAF giúp kết quả nghiên cứu của bạn đạt độ tin cậy học thuật cao hơn khi bảo vệ trước hội đồng luận văn.
4. Giải thích và đánh giá kết quả EFA trong luận văn tiếng anh
Việc đọc hiểu kết quả EFA đòi hỏi sự chính xác qua 03 bảng biểu quan trọng nhất trong kết quả xuất ra từ SPSS.
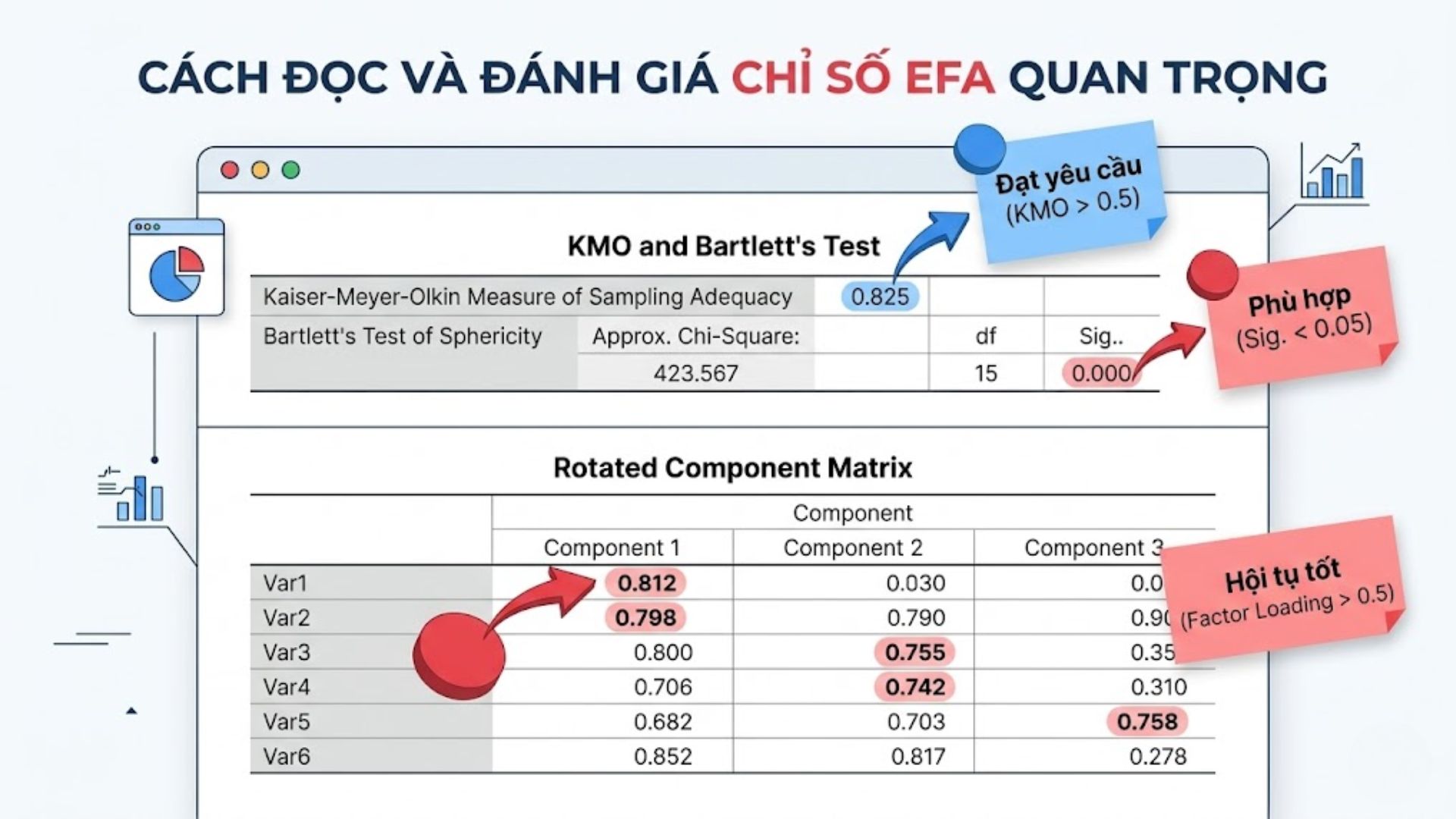
4.1. Diễn giải kết quả KMO và Bartlett’s test
Bảng KMO và Bartlett’s Test là “tấm vé” đầu tiên xác nhận bộ dữ liệu của bạn có ý nghĩa thống kê hay không.
| Chỉ số | Giá trị | Kết luận |
| KMO | 0.8 – 0.9 | Rất tốt (Meritorious) |
| KMO | 0.5 – 0.7 | Tạm ổn (Acceptable) |
| Bartlett’s Sig. | < 0.05 | Đạt yêu cầu phân tích |
Bảng đánh giá KMO cung cấp cái nhìn nhanh về độ tin cậy của mẫu nghiên cứu hiện tại.
Nếu Sig > 0.05, các biến không có tương quan và bạn không thể tiếp tục thực hiện phân tích nhân tố khám phá.
4.2. Cách xác định số lượng nhân tố cần trích xuất
Số lượng nhân tố được trích xuất quyết định sự tinh gọn của mô hình và được xác định dựa trên tiêu chuẩn Eigenvalue và Scree Plot.
-
Quy tắc Eigenvalue > 1: Chỉ những nhân tố có khả năng giải thích biến thiên tốt hơn một biến đơn lẻ mới được giữ lại.
-
Total Variance Explained: Tổng phương sai trích lũy phải đạt tối thiểu 50% để đảm bảo không mất quá nhiều thông tin.
-
Scree Plot: Điểm gãy của đường biểu diễn giúp xác định trực quan số lượng nhân tố nên dừng lại.
| Factor | Eigenvalue | % of Variance | Cumulative % |
| 1 | 3.520 | 35.2% | 35.2% |
| 2 | 1.840 | 18.4% | 53.6% |
Bảng Total Variance Explained minh họa cách các nhân tố bao quát thông tin của toàn bộ các biến quan sát ban đầu.
Việc dừng lại ở nhân tố có Eigenvalue > 1 là quy tắc phổ biến nhất trong các bài luận văn Thạc sĩ hiện nay.
4.3. Phân tích factor loading và xử lý biến
Hệ số tải nhân tố (Factor Loading) cho biết cường độ mối quan hệ giữa biến quan sát và nhân tố tiềm ẩn.
| Hệ số tải | Đánh giá | Hành động |
| < 0.3 | Rất thấp | Loại biến ngay lập tức |
| 0.3 – 0.5 | Tối thiểu | Cân nhắc giữ lại nếu mẫu lớn |
| > 0.5 | Tốt | Giữ lại để phân tích tiếp |
| Cross Loading | Tải lên 2 nhân tố | Loại nếu chênh lệch < 0.2 |
Bảng tiêu chuẩn hệ số tải giúp bạn ra quyết định loại bỏ các biến làm nhiễu mô hình nghiên cứu.
Sau khi loại một biến xấu, bạn phải chạy lại EFA từ đầu cho đến khi đạt được cấu trúc hội tụ và phân biệt.
5. Trình bày kết quả EFA trong luận văn tiếng anh
Sau khi phân tích, việc trình bày kết quả đúng chuẩn học thuật sẽ giúp bài luận của bạn trở nên chuyên nghiệp và dễ hiểu.
5.1. Cách trình bày bảng rotated component matrix
Ma trận xoay nhân tố là bảng quan trọng nhất để trình bày các biến quan sát đã được nhóm vào các nhân tố tương ứng.
| Biến quan sát | Factor 1 | Factor 2 | Factor 3 |
| CS1 | 0.824 | ||
| CS2 | 0.795 | ||
| PR1 | 0.812 |
Bảng ma trận xoay giúp người đọc hình dung rõ ràng cấu trúc của các thang đo sau khi phân tích.
Hãy in đậm (bold) các hệ số tải lớn nhất để làm nổi bật sự hội tụ của các biến vào từng nhân tố cụ thể.
5.2. Viết phần kết quả EFA bằng tiếng Anh học thuật
Trong luận văn tiếng Anh, bạn cần sử dụng các cấu trúc câu trang trọng để báo cáo thông số thống kê một cách chính xác.
-
Mẫu câu báo cáo KMO: “The KMO measure of sampling adequacy was 0.845, which exceeds the recommended threshold of 0.5.”
-
Mẫu câu báo cáo Bartlett: “Bartlett’s test of sphericity was statistically significant (p < 0.001), indicating that the data is suitable for factor analysis.”
-
Mẫu câu báo cáo Factor trích: “Six factors were extracted with eigenvalues greater than 1, explaining 63.35% of the total variance.”
Viết Thuê 247 khuyên bạn nên kết hợp giữa bảng biểu và đoạn văn mô tả để tối ưu hóa sự rõ ràng cho bài luận.
5.3. So sánh kết quả EFA trước và sau khi loại biến không đạt
Việc trình bày sự thay đổi sau khi làm sạch dữ liệu chứng minh quá trình nghiên cứu của bạn được thực hiện một cách nghiêm túc.
| Tiêu chí | Trước khi loại biến | Sau khi loại biến |
| Số biến quan sát | 28 | 26 |
| Số nhân tố | 7 | 6 |
| Tổng phương sai trích | 58.2% | 63.4% |
Bảng so sánh này làm nổi bật sự cải thiện về chất lượng của mô hình sau khi xử lý các biến xấu.
Loại bỏ biến không đạt giúp tăng độ hội tụ và làm cho các nhân tố trở nên có ý nghĩa lý thuyết rõ ràng hơn.
6. Ví dụ minh họa phân tích EFA trong luận văn và ứng dụng thực tế
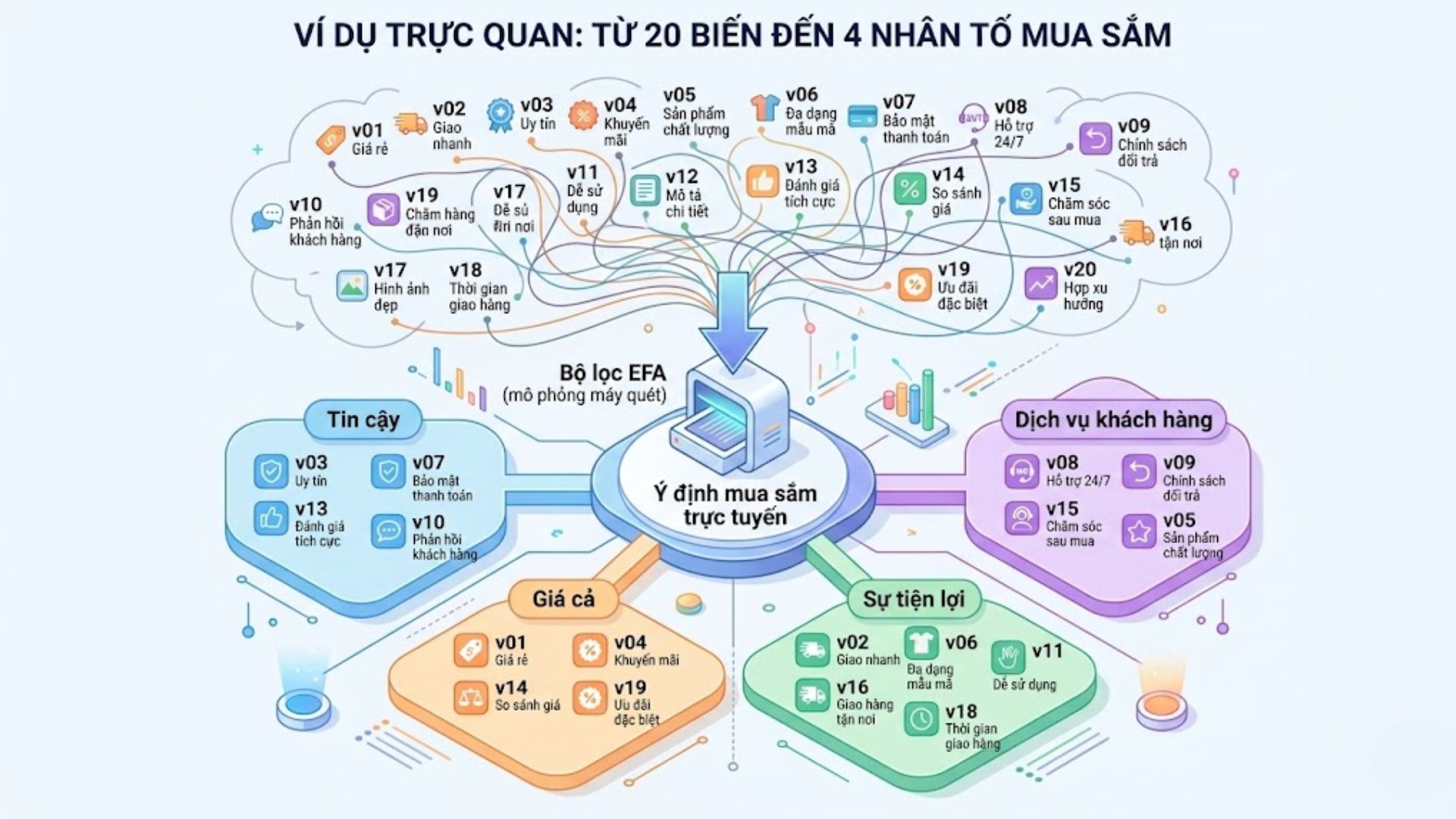
Giả sử bạn thực hiện nghiên cứu về “Các yếu tố ảnh hưởng đến ý định mua sắm trực tuyến” với mẫu n = 250. Sau khi chạy EFA cho 20 biến quan sát, kết quả KMO đạt 0.887 (rất tốt) và Bartlett’s test có Sig. = 0.000. SPSS trích xuất được 4 nhân tố có Eigenvalue > 1, bao gồm: Tin cậy, Giá cả, Sự tiện lợi và Dịch vụ khách hàng.
Tổng phương sai trích đạt 65%, nghĩa là 4 nhân tố này giải thích được 65% sự biến động của ý định mua sắm. Trong quá trình xoay nhân tố Varimax, biến “Thời gian giao hàng” bị loại do tải chéo (cross-loading) lên cả nhân tố Tin cậy và Tiện lợi với mức chênh lệch hệ số tải chỉ 0.12. Sau khi loại biến này và chạy lại, ma trận xoay đạt được giá trị phân biệt hoàn hảo, tạo tiền đề vững chắc cho bước hồi quy tiếp theo.
7. Những lỗi thường gặp khi phân tích EFA trong luận văn và cách khắc phục
Dưới đây là tổng hợp các lỗi phổ biến mà sinh viên thường mắc phải và giải pháp xử lý triệt để từ chuyên gia Viết Thuê 247.
| Lỗi thường gặp | Hệ quả | Giải pháp khắc phục |
| Mẫu quá nhỏ | Kết quả không ổn định, sai lệch | Tăng cỡ mẫu hoặc giảm số biến quan sát |
| Không chạy lại EFA | Sai lệch tổng phương sai trích | Phải chạy lại EFA mỗi khi loại bỏ một biến |
| Nhầm lẫn PCA và EFA | Sai lệch mục tiêu nghiên cứu | Chọn đúng Extraction Method (PAF cho nghiên cứu xã hội) |
| Giữ biến loading < 0.3 | Thang đo yếu, không đạt giá trị | Mạnh dạn loại bỏ các biến có hệ số tải thấp |
Bảng tổng hợp lỗi giúp bạn tự kiểm tra và chỉnh sửa bài luận của mình một cách chủ động.
-
Luôn kiểm tra hệ số tải chéo (Cross-loading): Nếu một biến tải lên nhiều nhân tố, hãy loại bỏ để đảm bảo tính phân biệt.
-
Đừng bỏ qua việc đặt tên nhân tố: Tên nhân tố mới phải phản ánh đúng nội dung của các biến quan sát bên trong.
-
Lưu ý về đơn vị đo lường: Nếu dữ liệu có đơn vị khác nhau (ví dụ: mét và kilometers), hãy chuẩn hóa về Z-score trước khi chạy.
8. FAQs về phân tích EFA trong luận văn

8.1. KMO bao nhiêu là đạt cho phân tích EFA?
Thông thường, chỉ số KMO phải đạt từ 0.5 trở lên để phân tích nhân tố được xem là phù hợp. Nếu KMO ≥ 0.7, bộ dữ liệu của bạn được đánh giá là tốt; nếu đạt trên 0.8, kết quả trích xuất sẽ có độ tin cậy rất cao.
8.2. Factor loading bao nhiêu là đạt?
Trong các nghiên cứu học thuật, hệ số tải nhân tố (factor loading) từ 0.5 trở lên được xem là đạt chất lượng tốt. Tuy nhiên, mức tối thiểu 0.3 có thể chấp nhận được nếu kích thước mẫu của bạn đủ lớn (thường trên 350 mẫu).
8.3. Có cần chạy EFA trước hồi quy không?
Có. EFA giúp xác nhận cấu trúc thang đo và giảm số lượng biến quan sát thành các nhân tố đại diện. Việc này đảm bảo mô hình hồi quy của bạn tinh gọn, chính xác và tránh được hiện tượng đa cộng tuyến.
8.4. Cỡ mẫu tối thiểu cho EFA là bao nhiêu?
Quy tắc phổ biến nhất là cần tối thiểu 100 mẫu cho một bài phân tích nhân tố. Ngoài ra, bạn nên đảm bảo tỷ lệ ít nhất 5 đến 10 quan sát cho mỗi biến quan sát trong mô hình nghiên cứu.
8.5. Sự khác biệt giữa EFA và CFA là gì?
EFA dùng để khám phá cấu trúc ẩn từ dữ liệu thô mà không cần giả thuyết trước. Ngược lại, CFA được sử dụng để kiểm định và xác nhận mức độ phù hợp của một mô hình lý thuyết đã được xác định từ trước.
Phân tích EFA là bước quan trọng để xác định giá trị thang đo, rút gọn biến và chuẩn bị dữ liệu cho hồi quy. Việc tuân thủ các chỉ số KMO, Bartlett và hệ số tải giúp luận văn đạt chuẩn khoa học quốc tế.
Viết Thuê 247 là đơn vị hàng đầu hỗ trợ xử lý số liệu SPSS và viết luận văn tiếng Anh chuyên nghiệp. Chúng tôi cam kết mang lại kết quả chính xác, bảo mật và đúng tiến độ cho mọi khách hàng.
Viết Thuê 247: Khi các bạn cần – chúng tôi có
-
Website: https://vietthue247.vn/
-
Hotline: 0904514345
-
Email: vietthue247@gmail.com

