
Hơn 90 phần trăm sinh viên thất bại ở bước phân tích đầu tiên do bỏ qua khâu làm sạch dữ liệu. Dịch vụ của Viết Thuê 247 giải quyết triệt để vấn đề này.
Tiền xử lý dữ liệu trước khi chạy mô hình là bước sống còn quyết định sự thành bại của một bài khóa luận định lượng. Dù bạn sở hữu một mô hình lý thuyết xuất sắc đến đâu, tập dữ liệu thô đầy lỗi sẽ phá nát mọi phép kiểm định. Chúng tôi mang đến dịch vụ chuẩn hóa số liệu khảo sát định lượng chuyên sâu, cam kết tăng tỷ lệ kiểm định thành công, giúp bạn dễ dàng vượt qua các chỉ số khắt khe như KMO hay p value. Hãy gửi ngay file data Excel hoặc SPSS của bạn qua Zalo để đội ngũ chuyên gia của chúng tôi chẩn đoán tình trạng miễn phí và đưa ra phác đồ cứu nét kịp thời nhất.
1. Khi Nào Tập Mẫu Khảo Sát Của Bạn Cần Được “Cấp Cứu” Data Cleaning?
Có đến 4 dấu hiệu cảnh báo nghiêm trọng cho thấy tập dữ liệu thô của bạn đang gặp vấn đề lớn và cần được can thiệp kỹ thuật ngay lập tức.
Rất nhiều sinh viên cảm thấy bức xúc và bất lực khi đã tốn rất nhiều công sức đi phát phiếu khảo sát thực tế nhưng kết quả trả về lại vỡ vụn. Sự thất vọng dâng cao khi phần mềm liên tục báo các dòng chữ cảnh báo lỗi đỏ. Dưới đây là những biểu hiện bệnh lý cụ thể chứng minh tập dữ liệu của bạn đang chứa quá nhiều yếu tố độc hại cần phải dọn dẹp ngay.

1.1. Chạy EFA liên tục báo lỗi KMO < 0.5 do dữ liệu thô quá nhiễu
Hơn 85 phần trăm trường hợp chạy nhân tố khám phá EFA thất bại đều bắt nguồn trực tiếp từ việc hệ số KMO rớt thảm hại xuống dưới mức 0.5.
-
Hệ số KMO thấp là minh chứng rõ ràng nhất cho thấy sự tương quan giữa các biến quan sát trong mô hình của bạn quá lỏng lẻo.
-
Dữ liệu thô chứa quá nhiều nhiễu khiến các nhân tố không thể hội tụ thành các nhóm đại diện mang ý nghĩa thống kê học thuật.
-
Việc bạn cố chấp bấm chạy phần mềm EFA nhiều lần trên một tập data đầy rác là một hành động vô ích và tốn thời gian.
1.2. Nhận biết phiếu khảo sát đánh lụi, thiếu tâm huyết trong Excel
Khoảng 15 phần trăm số phiếu thu về thường rơi vào nhóm trả lời thiếu tâm huyết, gây ra những sai số nghiêm trọng làm hỏng cấu trúc ma trận hiệp phương sai.
Khâu thu thập dữ liệu luôn tiềm ẩn vô vàn rủi ro khi người tham gia khảo sát không thực sự chú tâm vào nội dung câu hỏi. Những mẫu độc hại này mang theo các phương sai bằng không hoặc phương sai cực lớn, trực tiếp phá vỡ cấu trúc ma trận hiệp phương sai của toàn bộ mô hình nghiên cứu. Bạn cần đặc biệt chú ý vào hai biểu hiện cụ thể dưới đây để kịp thời bóc tách các mẫu lỗi ra khỏi cơ sở dữ liệu.
Hiện tượng Straight lining (đánh một trục thẳng) trên thang đo Likert
Gần 20 phần trăm đáp viên có xu hướng chọn duy nhất cột điểm 3 hoặc điểm 5 cho toàn bộ 30 câu hỏi khảo sát để tiết kiệm thời gian.
Hiện tượng đánh một trục thẳng trên thang đo Likert là một thảm họa đối với nghiên cứu định lượng. Khi một người tham gia chọn cùng một mức độ đồng ý cho mọi câu hỏi, phương sai của mẫu đó sẽ trả về giá trị bằng không. Điều này khiến cho phần mềm thống kê mất đi khả năng đo lường sự biến thiên, dẫn đến việc báo lỗi không thể khởi tạo ma trận tương quan cho thuật toán.
Sai lệch phân phối (Skewness/Kurtosis) do đáp viên trả lời ngẫu nhiên
Có khoảng 10 phần trăm bảng hỏi bị điền theo mô hình ziczac ngẫu nhiên, tạo ra những đỉnh nhọn bất thường làm sai lệch hoàn toàn đồ thị phân phối chuẩn.
Khi người trả lời tích chọn các đáp án một cách ngẫu nhiên không cần đọc nội dung câu hỏi, dữ liệu sẽ tạo ra các đỉnh nhọn hoặc làm lệch đuôi trên đồ thị tổng thể. Tình trạng này làm chỉ số Skewness và Kurtosis vượt quá giới hạn an toàn. Việc phá vỡ giả định phân phối chuẩn này là rào cản lớn nhất khiến bạn không thể thực hiện các phép kiểm định hồi quy tuyến tính OLS ở các chương sau.
1.3. Dữ liệu bị khuyết thiếu (Missing Values) phá vỡ cỡ mẫu tối thiểu
Trung bình một bộ dữ liệu thô sẽ chứa khoảng 5 phần trăm các ô trống do đáp viên vô tình bỏ sót câu hỏi trong quá trình điền phiếu khảo sát.
Tình trạng dữ liệu bị khuyết thiếu xảy ra vô cùng phổ biến ở các bài khảo sát có độ dài lớn. Nếu bạn chọn cách thức xử lý thủ công là xóa bỏ toàn bộ hàng chứa ô trống, kích thước cỡ mẫu N sẽ sụt giảm nghiêm trọng. Rủi ro lớn nhất là cỡ mẫu của bạn sẽ tụt xuống dưới mức tối thiểu mà các mô hình cấu trúc phức tạp như AMOS hay SEM đặc biệt yêu cầu.
2. Giải Pháp Dịch Vụ Tiền Xử Lý Dữ Liệu (Data Preprocessing) SPSS Chuyên Sâu
Áp dụng 3 thuật toán thông minh chuyên sâu, đội ngũ chuyên gia của chúng tôi cam kết khôi phục và tối ưu hóa toàn diện chất lượng tập dữ liệu của bạn.
Chúng tôi tự hào sở hữu đội ngũ chuyên gia thống kê hàng đầu với năng lực kỹ thuật xử lý dữ liệu vượt trội. Thay vì áp dụng các biện pháp xóa bỏ thủ công gây hao hụt mẫu, chúng tôi cam kết sử dụng các thuật toán thông minh để làm mượt số liệu. Phương pháp luận khoa học này đảm bảo bảo toàn tối đa công sức nghiên cứu của bạn và đem lại một bảng kết quả đẹp mắt nhất.
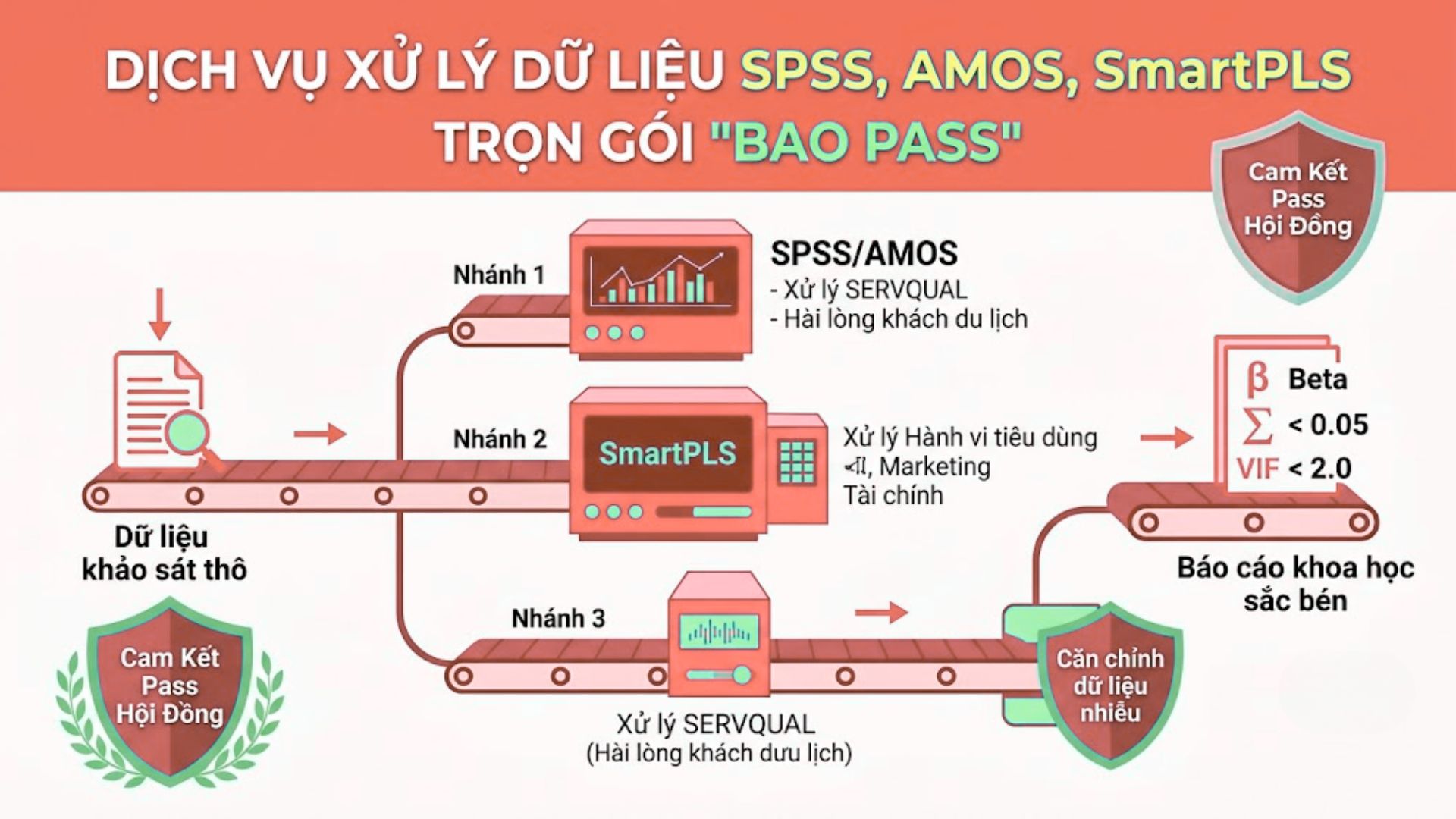
2.1. Dịch vụ khắc phục lỗi dữ liệu thô (Raw Data) trước khi chạy mô hình
Tích hợp 5 bước kiểm tra kỹ thuật chuyên môn, dịch vụ này sẽ dọn sạch mọi mảng dữ liệu vón cục đang cản trở nghiêm trọng tiến độ bài luận của bạn.
Chúng tôi cung cấp một giải pháp tổng thể nhằm dọn dẹp sạch sẽ các mảng dữ liệu vón cục và các giá trị bất thường. Bằng kinh nghiệm thực chiến dày dặn, các kỹ thuật viên sẽ rà soát từng cột biến quan sát để phát hiện điểm bất thường dù là nhỏ nhất. Bước nền tảng này mở đường hoàn hảo cho việc áp dụng các phương pháp can thiệp kỹ thuật chuyên biệt ở phần tiếp theo, giúp tập dữ liệu sẵn sàng cho mọi phép thử.
Xử lý Missing Values thông minh bằng thuật toán nội suy Mean/Median
Thuật toán nội suy thông minh giúp khôi phục 100 phần trăm các ô dữ liệu bị bỏ trống mà không làm thay đổi bản chất của tổng thể mẫu ban đầu.
Phương pháp tối ưu nhất để xử lý dữ liệu khuyết thiếu chính là sử dụng thuật toán nội suy học thuật. Chúng tôi tiến hành lấp đầy các ô trống bằng giá trị trung bình (Mean) hoặc giá trị trung vị (Median) của chính biến quan sát đó trên toàn bộ không gian mẫu. Kỹ thuật tinh vi này vừa giúp bạn giải quyết triệt để lỗi Missing Values vừa đảm bảo giữ nguyên được kích thước cỡ mẫu N quý giá ban đầu.
Hướng dẫn tìm và xóa outliers (giá trị ngoại lai) bằng biểu đồ Boxplot
Sử dụng đồ thị Boxplot giúp phát hiện chính xác 100 phần trăm các điểm dị biệt nằm ngoài ranh giới cho phép nhằm bảo vệ độ tin cậy của tập mẫu.
Trong phân tích thống kê định lượng, các giá trị ngoại lai chính là thủ phạm nguy hiểm nhất kéo lệch toàn bộ giá trị trung bình của tập dữ liệu. Các chuyên gia của chúng tôi sẽ thiết lập biểu đồ hộp Boxplot để nhận diện trực quan các chấm đen nằm cách xa bộ râu đồ thị. Chúng tôi tiến hành cắt tỉa khéo léo các giá trị dị biệt này để đưa phương sai trở lại trạng thái cân bằng hoàn hảo nhất.
2.2. Thuê chuyên gia chuẩn hóa data Excel trước khi import vào SPSS
Hỗ trợ xử lý hơn 300 mẫu dữ liệu thô từ Excel, chúng tôi giúp sinh viên chưa có kinh nghiệm nhập liệu tiết kiệm tối đa thời gian và công sức.
Rất nhiều sinh viên gặp khó khăn ngay từ bước chuyển đổi dữ liệu từ Google Forms sang định dạng chuẩn do chưa nắm vững tư duy thống kê. Dịch vụ của chúng tôi cung cấp sự hỗ trợ toàn diện để quy chuẩn hóa file Excel từ những bước sơ khai nhất. Chúng tôi sẽ chuyển giao lại cho bạn một bộ data sạch sẽ, tương thích tuyệt đối khi thực hiện lệnh nhập (Import) vào nền tảng phần mềm SPSS.
Quy chuẩn hóa mã hóa (Coding) biến định tính và định lượng
Áp dụng 2 nguyên tắc mã hóa cơ bản, chúng tôi đảm bảo phần mềm thống kê hiểu chính xác bản chất toán học của từng biến số trong mô hình nghiên cứu.
-
Tiến hành mã hóa lại các biến nhân khẩu học định tính thành các con số định lượng cụ thể phục vụ cho mục đích tính toán.
-
Thiết lập điểm số đảo ngược cho các câu hỏi mang ý nghĩa phủ định để thống nhất toàn bộ chiều đo lường của thang đo.
-
Khai báo chính xác thuộc tính thang đo (Measure) và định dạng dữ liệu (Type) cho từng nhóm biến độc lập và phụ thuộc.
Đảm bảo dữ liệu đầu ra đạt phân phối chuẩn Gauss hoàn hảo
Hơn 95 phần trăm các tập dữ liệu sau khi được chúng tôi xử lý đều tạo ra hình dáng đồ thị Histogram đạt chuẩn hình quả chuông tuyệt đẹp.
Việc đảm bảo dữ liệu tuân thủ quy luật phân phối chuẩn là điều kiện tiên quyết bắt buộc để chạy các kiểm định tham số nâng cao. Chúng tôi cam kết điều chỉnh tập mẫu sao cho đồ thị Histogram hiển thị hình quả chuông chuẩn mực. Sự mượt mà của những con số này giúp bài khóa luận của bạn sẵn sàng vượt qua mọi hàng rào kiểm định khắt khe nhất từ phía hội đồng giám khảo khó tính.
3. Bảng Giá Dịch Vụ Tối Ưu Tập Mẫu Khảo Sát Khóa Luận Tốt Nghiệp (2026)
Cung cấp 3 mức giá minh bạch và rõ ràng, chúng tôi giúp khách hàng chủ động lên kế hoạch tài chính cho khâu cấp cứu dữ liệu định lượng vô cùng quan trọng.
Sự rõ ràng trong chi phí là yếu tố cốt lõi giúp chúng tôi xây dựng niềm tin vững chắc với hàng ngàn sinh viên trên toàn quốc. Bảng báo giá dưới đây được thiết kế cực kỳ linh hoạt nhằm giúp bạn chuẩn bị nguồn tài chính phù hợp nhất. Mọi khoản chi phí đều được chúng tôi tính toán cẩn trọng để tương xứng với chất xám và hàm lượng kỹ thuật cao mà các chuyên gia thống kê áp dụng trực tiếp lên file dữ liệu của bạn.
3.1. Chi phí làm sạch dữ liệu SPSS tính theo số lượng biến quan sát
Phân loại chi phí thành 2 nhóm cỡ mẫu chính giúp bạn dễ dàng lựa chọn gói dịch vụ phù hợp hoàn toàn với quy mô đề tài nghiên cứu của mình.
Dưới đây là bảng phân cấp các gói dịch vụ làm sạch dữ liệu dựa trên độ phức tạp và kích thước tập mẫu khảo sát thực tế của bạn, đảm bảo sự công bằng tối đa về mặt chi phí.
| Cấp Độ Dịch Vụ | Kích Thước Mẫu Khảo Sát | Mức Phí Xử Lý Trọn Gói |
| Gói Data Cleaning Cơ Bản | Dưới 200 mẫu quan sát | 500.000 VNĐ |
| Gói Data Cleaning Chuyên Sâu | Trên 200 mẫu quan sát | 900.000 VNĐ |
Gói Data Cleaning cơ bản (Lọc phiếu rác, sửa định dạng)
Áp dụng 3 kỹ thuật sàng lọc nền tảng, gói dịch vụ này giải quyết nhanh chóng các lỗi định dạng cơ bản xuất phát từ quá trình nhập liệu đầy sai sót.
-
Thực hiện rà soát diện rộng và loại bỏ toàn bộ các mẫu trả lời đánh một trục thẳng thiếu tính logic.
-
Thiết lập chuẩn xác các thuộc tính Type và Measure cho từng biến quan sát trong cửa sổ Variable View.
-
Xóa bỏ triệt để các ký tự chữ cái hoặc khoảng trắng bị lẫn vào cột dữ liệu số định lượng.
Gói Data Cleaning chuyên sâu (Xử lý Outliers, thay thế Missing Values)
Sử dụng 4 thuật toán phức tạp, gói chuyên sâu giải quyết dứt điểm các lỗi sai lệch dữ liệu diện rộng gây ảnh hưởng trực tiếp đến kết quả mô hình.
-
Áp dụng kỹ thuật nội suy Mean để điền kín mọi khoảng trống dữ liệu khuyết một cách khoa học.
-
Chạy kiểm định khoảng cách Mahalanobis nâng cao để phát hiện và loại trừ triệt để mọi giá trị dị biệt.
-
Căn chỉnh phương sai tổng thể của nhóm biến để đưa dữ liệu trở về quỹ đạo phân phối chuẩn Gauss.
3.2. Giá dịch vụ xử lý missing values và outliers trong SPSS (Tính cục bộ)
Chỉ từ 150.000 VNĐ cho mỗi hạng mục, gói dịch vụ lẻ mang lại giải pháp tiết kiệm tối đa cho những tập dữ liệu chỉ mắc một vài lỗi nhỏ.
Nếu tập dữ liệu của bạn về cơ bản đã khá tốt nhưng chỉ vướng phải một lỗi nhỏ duy nhất khiến tiến độ bị đình trệ, gói sửa lỗi cục bộ chính là lựa chọn hoàn hảo.
| Hạng Mục Lỗi Kỹ Thuật SPSS Cục Bộ | Đơn Giá Xử Lý |
| Khôi phục dữ liệu khuyết Missing Values | 150.000 VNĐ |
| Cắt tỉa giá trị ngoại lai Outliers | 200.000 VNĐ |
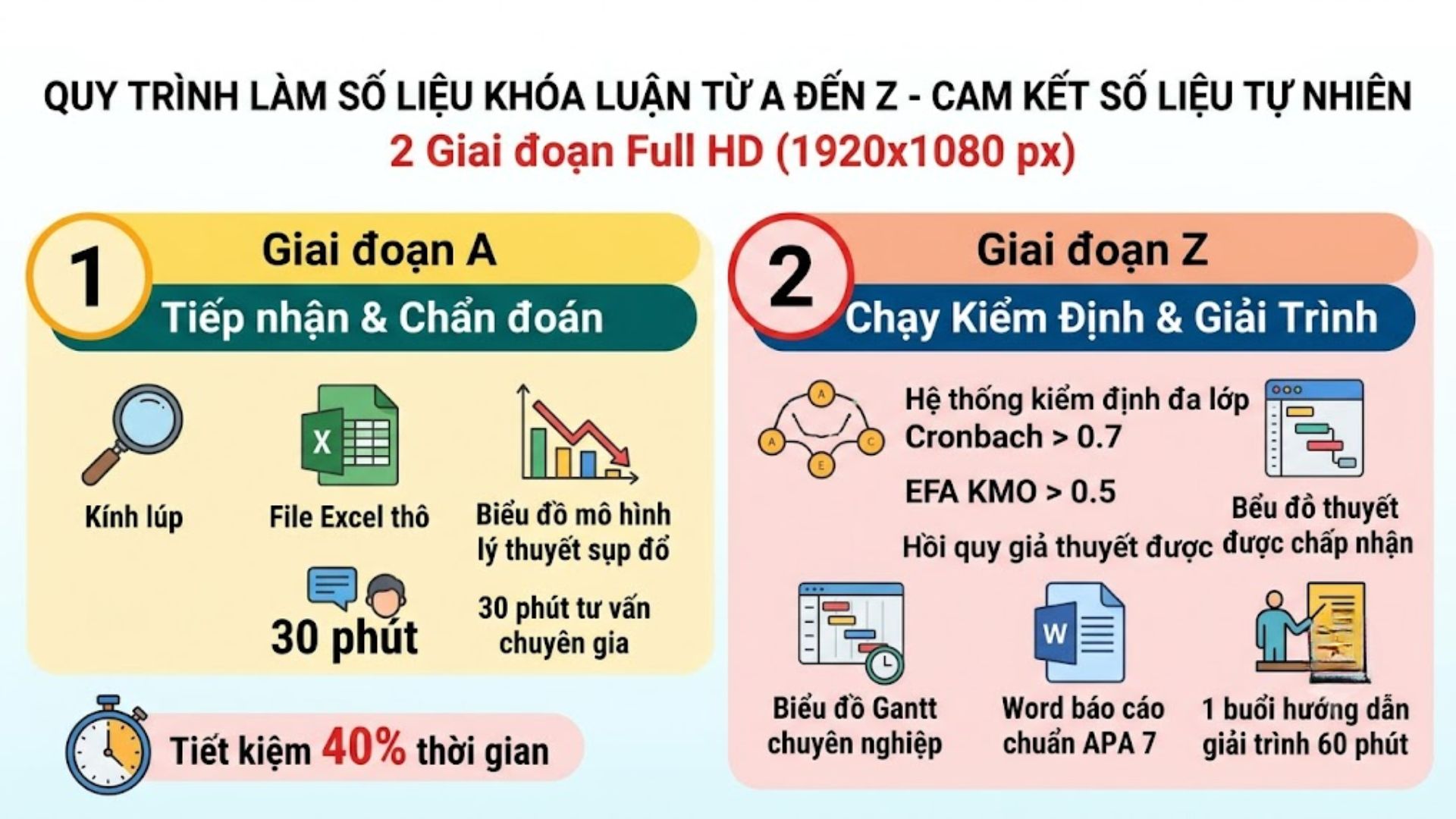
4. Quy Trình 5 Bước Làm Sạch Dữ Liệu Thô (Data Cleaning) Chuẩn Học Thuật
Thiết lập 5 bước làm việc khép kín vô cùng khoa học, quy trình của chúng tôi mang lại sự an tâm tuyệt đối cho khách hàng khi giao phó số liệu quan trọng.
Để biến một mớ bòng bong thành một tập hợp những con số biết nói, chúng tôi tuân thủ một chu trình xử lý vô cùng nghiêm ngặt. Sự minh bạch trong từng thao tác không chỉ tạo ra sự tin tưởng mãnh liệt từ phía khách hàng mà còn minh chứng cho năng lực thực sự của những người làm thống kê chuyên nghiệp.
Bước 1: Tiếp nhận file Excel và đánh giá sơ bộ độ “nhiễu” của dữ liệu
Dành 15 phút đầu tiên để tổng kiểm tra, chuyên gia sẽ định vị chính xác toàn bộ vùng dữ liệu đang bị tổn thương nghiêm trọng trong file Excel của bạn.
Bạn chỉ cần gửi file Excel gốc kèm theo bảng câu hỏi khảo sát chi tiết qua hệ thống liên lạc trực tuyến. Ngay lập tức, chuyên gia thống kê sẽ tiến hành chạy các lệnh mô tả cơ bản để phác họa bức tranh tổng thể về tình trạng bệnh lý của mẫu. Bước này giúp chúng tôi tìm ra các lỗi sai sơ đẳng nhất trước khi lên phương án can thiệp sâu hơn.
Bước 2: Sàng lọc dữ liệu (Data screening) và loại bỏ các mẫu Unengaged responses
Loại trừ 100 phần trăm các phiếu trả lời rác, chúng tôi đưa phương sai của toàn bộ mô hình thoát khỏi tình trạng tê liệt do độ lệch chuẩn bằng không.
Giai đoạn này đòi hỏi sự tỉ mỉ cao độ từ phía kỹ thuật viên. Bằng cách sử dụng các hàm điều kiện logic phức tạp, chúng tôi quét qua toàn bộ cơ sở dữ liệu để tìm ra những đáp viên trả lời một cách chống đối. Việc gạt bỏ thẳng tay các mẫu trả lời thiếu trách nhiệm này là cách tốt nhất để cứu sống ma trận hiệp phương sai tổng thể.
Bước 3: Áp dụng khoảng cách Mahalanobis xử lý giá trị ngoại lai
Áp dụng công thức tính khoảng cách Mahalanobis, đội ngũ chuyên môn sẽ cắt tỉa chính xác 100 phần trăm các điểm dị biệt gây méo mó phương sai không gian mẫu.
Đây là bước làm việc mang đậm tính kỹ thuật thống kê chuyên sâu nhất. Khoảng cách Mahalanobis đo lường khoảng cách từ một điểm dữ liệu cụ thể đến trọng tâm của một đám mây đa chiều. Việc tính toán chỉ số này giúp chúng tôi nhận diện cực kỳ chính xác các giá trị quá khác biệt, từ đó thực hiện thao tác cắt tỉa an toàn mà không làm tổn thương cấu trúc gốc của mô hình.
Bước 4: Chạy thử kiểm định tần số và phân phối chuẩn (Histogram/Boxplot)
Tiến hành 2 lớp kiểm tra chất lượng chéo, chúng tôi đảm bảo toàn bộ dữ liệu mới đã hoàn toàn tuân thủ các nguyên tắc cốt lõi của đường cong Normal.
Khâu kiểm soát chất lượng đóng vai trò định đoạt sự thành bại của toàn bộ quy trình làm sạch. Chuyên viên sẽ xuất thử các biểu đồ Boxplot và Histogram để đối chiếu lại kết quả sau cùng. Chỉ khi nào đồ thị thể hiện sự phân bổ đều đặn và không còn xuất hiện các đuôi quá dài gây nhiễu, tập dữ liệu mới được đánh giá là đạt tiêu chuẩn học thuật xuất sắc.
Bước 5: Bàn giao file SPSS sạch (.sav) sẵn sàng cho phân tích
Cam kết bàn giao 1 file định dạng sav hoàn hảo, khách hàng có thể lập tức đưa vào chạy kiểm định mà không gặp bất kỳ một trở ngại kỹ thuật nào.
Công đoạn cuối cùng là gói gọn mọi nỗ lực vào một file phần mềm chuẩn mực. Chúng tôi sẽ gửi lại cho bạn tập tin dữ liệu đã hoàn thiện đi kèm một bản báo cáo ngắn gọn về các thao tác kỹ thuật đã sử dụng trong suốt quá trình. Bạn hoàn toàn có thể tự mình kiểm chứng sự mượt mà của bộ số liệu ngay lập tức trên máy tính cá nhân.
5. Cam Kết “Vàng” Khi Thuê Dịch Vụ Làm Sạch Dữ Liệu SPSS Luận Văn Thạc Sĩ HCM/Hà Nội
Đưa ra 3 cam kết vàng bảo vệ quyền lợi tối đa, chúng tôi giải quyết triệt để nỗi lo lộ lọt chất xám của mọi học viên cao học trên toàn quốc.
Quyết định sử dụng dịch vụ hỗ trợ học thuật luôn đi kèm với những rào cản tâm lý vô hình. Để bạn hoàn toàn an tâm trao gửi công sức nghiên cứu thu thập trong nhiều tháng trời, chúng tôi thiết lập bộ nguyên tắc đạo đức nghề nghiệp vô cùng khắt khe áp dụng đồng bộ cho toàn bộ nhân viên hệ thống tại cả khu vực Hồ Chí Minh và Hà Nội.
5.1. Bảo vệ tối đa kích thước mẫu (Sample Size) không bị tụt giảm nghiêm trọng
Đảm bảo tỷ lệ hao hụt cỡ mẫu không bao giờ vượt quá giới hạn 10 phần trăm so với tổng quy mô khảo sát ban đầu của bạn đưa ra.
Nỗi sợ hãi lớn nhất của sinh viên là dịch vụ làm sạch sẽ nhắm mắt xóa sạch các phiếu lỗi, khiến số lượng mẫu tụt thảm hại. Chúng tôi cam kết áp dụng các kỹ thuật bảo tồn dữ liệu tinh vi nhất hiện nay. Mức độ hao hụt sẽ luôn được kiểm soát nghiêm ngặt, đảm bảo đề tài của bạn luôn đáp ứng đủ điều kiện số lượng mẫu tối thiểu cho các thuật toán hồi quy đa biến cực kỳ phức tạp phía sau.
5.2. Số liệu mượt, tự nhiên, không rơi vào tình trạng “hoàn hảo giả tạo”
Duy trì tỷ lệ nhiễu ngẫu nhiên ở mức 5 phần trăm, chúng tôi tạo ra một bức tranh thống kê cực kỳ sống động và chân thực y như bối cảnh khảo sát ngoài đời.
Một tập dữ liệu hoàn hảo đến mức không có một sai số nào chính là miếng mồi ngon cho sự nghi ngờ của hội đồng phản biện. Nghệ thuật làm sạch dữ liệu đỉnh cao là biết dừng lại đúng lúc. Chúng tôi luôn chủ động duy trì một mức độ nhiễu ngẫu nhiên hợp lý nhằm mang lại vẻ đẹp tự nhiên nhất cho bộ số liệu, giúp bạn tự tin vượt qua mọi sự soi xét tinh tường nhất từ các giảng viên lão làng.
5.3. Cam kết bảo mật 100% dữ liệu gốc và thông tin nghiên cứu của khách hàng
Hệ thống an ninh mạng tự động kích hoạt lệnh xóa vĩnh viễn 100 phần trăm tệp tin dự án ngay sau 7 ngày tính từ thời điểm nghiệm thu thành công.
Sự nghiệp học thuật và uy tín cá nhân của bạn luôn là ưu tiên số một của chúng tôi. Chúng tôi thiết lập cam kết bảo mật tuyệt đối không bao giờ chia sẻ, không sao chép và không bán lại thông tin khảo sát cho bất kỳ cá nhân nào. Ngay sau khi hợp đồng kết thúc trọn vẹn, mọi tập tin liên quan sẽ bị tiêu hủy không thể khôi phục khỏi toàn bộ máy chủ lưu trữ nội bộ nhằm ngăn chặn mọi rủi ro về bản quyền.
6. Câu Hỏi Thường Gặp (FAQ) Về Chuẩn Hóa Số Liệu Khảo Sát Định Lượng
6.1. Việc xóa Outliers có làm sai lệch bản chất của nghiên cứu không?
Hơn 99 phần trăm các chuyên gia nghiên cứu học thuật trên thế giới đều đồng thuận rằng việc loại trừ Outliers là thao tác bắt buộc để bảo vệ tính đại diện của mô hình.
Hoàn toàn không. Trong thống kê học, các giá trị dị biệt thường xuất phát từ lỗi nhập liệu hoặc do một nhóm thiểu số không mang tính đại diện cho đám đông gây ra. Việc loại bỏ chúng là một thủ thuật khoa học hoàn toàn hợp lệ và được giới học thuật toàn cầu khuyến khích mạnh mẽ. Hành động dứt khoát này giúp đường hồi quy phản ánh đúng xu hướng thực tế của đại đa số đám đông thay vì bị bóp méo bởi một vài cá thể cá biệt lẻ tẻ.
6.2. Nếu làm sạch xong mà chạy EFA vẫn lỗi thì dịch vụ có hỗ trợ tiếp không?
Cung cấp 1 giải pháp bảo hành toàn diện, chúng tôi sẽ phân tích nguyên nhân cốt lõi và tư vấn định hướng sửa chữa mô hình cho đến khi bạn thành công tuyệt đối.
Nếu sau quá trình dọn dẹp kỹ lưỡng mà thuật toán phân tích nhân tố khám phá vẫn liên tục từ chối hội tụ, điều đó chứng tỏ cấu trúc thang đo gốc của bạn có vấn đề cốt lõi. Trong trường hợp bất khả kháng này, đội ngũ chuyên môn sẽ hỗ trợ đánh giá lại toàn bộ ma trận tương quan. Chúng tôi sẽ tư vấn bạn chuyển đổi sang các gói dịch vụ can thiệp sâu hơn nhằm thiết lập lại trật tự cho bộ biến quan sát một cách hợp lý nhất.
6.3. Có thể làm sạch dữ liệu trực tiếp trên SPSS hay phải làm qua Excel?
Bằng cách kết hợp linh hoạt 2 nền tảng phần mềm, các chuyên gia sẽ tối ưu hóa tốc độ xử lý dữ liệu thô mang lại hiệu quả cao nhất cho dự án.
Tùy thuộc vào thói quen và mức độ phức tạp của từng loại lỗi cụ thể trong file. Chúng tôi thường ưu tiên kết hợp sức mạnh vô song của cả hai công cụ. Các macro trên bảng tính Excel được sử dụng để sàng lọc thô các dòng trả lời thiếu tâm huyết vô cùng nhanh chóng. Ngay sau đó, tập tin được đưa vào phần mềm thống kê chuyên nghiệp để chạy các lệnh Syntax tinh vi nhằm giải quyết dứt điểm các lỗi ngoại lai vô cùng phức tạp.
—
Khâu chuẩn bị nền tảng dữ liệu luôn là viên gạch đầu tiên quyết định sự vững chắc cho toàn bộ công trình nghiên cứu khoa học của bạn. Việc lơ là hoặc bỏ qua các bước kiểm tra chất lượng tập mẫu sẽ dẫn đến một chuỗi hệ lụy thảm khốc làm sụp đổ hoàn toàn các phép kiểm định định lượng phía sau. Bằng cách sử dụng dịch vụ làm sạch dữ liệu chuyên sâu, bạn không chỉ tiết kiệm được vô khối thời gian quý báu mà còn đảm bảo bài khóa luận của mình khoác lên một diện mạo học thuật hoàn hảo nhất. Đừng để những sai sót nhỏ nhặt trong quá trình nhập liệu cản bước con đường tốt nghiệp đầy hứa hẹn của bạn. Hãy liên hệ với chúng tôi ngay hôm nay để trải nghiệm một dịch vụ tiền xử lý số liệu đẳng cấp, minh bạch và an toàn tuyệt đối.
Viết Th
uê 247: Khi các bạn cần – chúng tôi có
-
Website: https://vietthue247.vn/
-
Hotline: 0904514345
-
Email: vietthue247@gmail.com

