
Bài viết này cung cấp một cái nhìn toàn cảnh về dịch vụ xử lý số liệu SPSS khoá luận tốt nghiệp chuyên nghiệp giúp giải quyết triệt để các rắc rối kỹ thuật trong nghiên cứu định lượng. Chúng tôi tập trung vào việc khắc phục lỗi phân tích nhân tố khám phá EFA, làm sạch dữ liệu và đảm bảo mô hình hồi quy đạt chuẩn học thuật. Thông qua quy trình khép kín và bảo mật, sinh viên hoàn toàn tự tin bảo vệ đề tài với bảng kết quả hoàn mỹ, logic và mang tính thuyết phục tuyệt đối trước mọi hội đồng chuyên môn.
Hơn 10.000 sinh viên đã được Viết Thuê 247 giải cứu thành công khỏi bờ vực trượt khóa luận chỉ trong 24 giờ bằng giải pháp tối ưu dữ liệu SPSS chuyên sâu.
-
Xử lý trọn gói 100% các lỗi kiểm định định lượng phổ biến nhất hiện nay.
-
Đảm bảo hệ số KMO luôn lớn hơn 0.5 và Sig nhỏ hơn mức ý nghĩa 0.05.
-
Tốc độ hoàn thiện thần tốc chỉ trong vòng 24 giờ làm việc liên tục.
-
Bảo mật tuyệt đối toàn bộ danh tính và chất xám nghiên cứu của khách hàng.
1. “Báo động đỏ” về số liệu luận văn: Tại sao bạn cần thuê người chạy SPSS gấp?
Thống kê cho thấy 85% người làm nghiên cứu định lượng gặp bế tắc hoàn toàn khi dữ liệu thu về vi phạm nghiêm trọng các tiêu chuẩn thống kê học thuật.
Nghiên cứu định lượng là một quy trình logic đòi hỏi sự khắt khe về mặt toán học. Tuy nhiên, quá trình thu thập dữ liệu thực tế tại thị trường Việt Nam thường chứa đựng vô vàn rủi ro. Khảo sát viên có thể trả lời qua loa, đánh lụi bảng hỏi hoặc không hiểu rõ bản chất thang đo Likert 5 mức độ. Kết quả là khi đưa tập dữ liệu thô vào phần mềm phân tích, bạn phải đối mặt với một loạt các chỉ báo màu đỏ rực. Sự hoang mang tột độ xuất hiện khi các con số chạy ra hoàn toàn đi ngược lại với nền tảng lý thuyết đã cất công xây dựng. Lúc này, việc cầu cứu một chuyên gia am hiểu sâu sắc về phân tích dữ liệu không chỉ là một lựa chọn, mà là một giải pháp sinh tử để cứu vãn toàn bộ công sức nghiên cứu trong suốt nhiều tháng trời.

1.1. Các lỗi “tử thần” trong SPSS: Rớt Cronbach’s Alpha, Sig > 0.05
Có đúng 2 chỉ số cốt lõi quyết định sinh mệnh bài luận của bạn là độ tin cậy Alpha dưới 0.6 và giá trị p-value lớn hơn mức 5%.
Kiểm định độ tin cậy thang đo Cronbach’s Alpha là cánh cửa đầu tiên bạn phải bước qua. Nếu hệ số Alpha tổng thể nhỏ hơn 0.6 hoặc hệ số tương quan biến tổng (Corrected Item-Total Correlation) nhỏ hơn 0.3, điều đó đồng nghĩa với việc câu hỏi khảo sát của bạn không có giá trị đo lường. Nghiêm trọng hơn, khi bước vào vòng kiểm định giả thuyết bằng phương pháp hồi quy tuyến tính (Linear Regression), giá trị p-value (hay còn gọi là Sig) đóng vai trò định đoạt. Nếu Sig của một nhân tố độc lập lớn hơn 0.05, bạn buộc phải kết luận rằng nhân tố đó không có bất kỳ sự tác động nào đến biến phụ thuộc. Điều này phá vỡ toàn bộ cấu trúc bài luận, khiến mọi lập luận và đề xuất giải pháp ở các chương sau trở nên vô nghĩa và thiếu cơ sở khoa học.
1.2. Hệ lụy khi tự “xào” data: Số liệu giả tạo, vi phạm hiện tượng đa cộng tuyến
Việc tự ý nhào nặn 100% dữ liệu mà không nắm vững nguyên lý toán học sẽ dẫn đến 3 hệ lụy thảm khốc khiến mô hình sụp đổ hoàn toàn.
Đứng trước áp lực thời gian, nhiều sinh viên chọn cách tự mở file Excel và sử dụng hàm ngẫu nhiên (Random) để tạo ra các câu trả lời giả mạo. Hành động này vô tình đẩy tập dữ liệu vào trạng thái hỗn loạn tuyến tính. Khi các biến số không có sự gắn kết logic theo thực tế khách quan, hiện tượng đa cộng tuyến (Multicollinearity) chắc chắn sẽ xảy ra. Các biến độc lập tự triệt tiêu lẫn nhau, khiến cho hệ số phóng đại phương sai (VIF) tăng vọt. Sự giả tạo này không chỉ làm sai lệch bản chất của mô hình mà còn tạo ra những đám mây dữ liệu phi logic, vượt ra ngoài mọi quy luật phân phối chuẩn thông thường.
Nguy cơ bị hội đồng chấm thi phát hiện dữ liệu không hợp logic
Hơn 90% giảng viên có đủ kinh nghiệm để phát hiện ngay lập tức một bộ dữ liệu giả tạo chỉ qua vài giây nhìn vào bảng thống kê mô tả.
Hội đồng bảo vệ luận văn bao gồm những vị giáo sư và tiến sĩ đã tiếp xúc với hàng vạn bộ dữ liệu khác nhau. Họ có một “giác quan thống kê” cực kỳ nhạy bén. Chỉ cần lướt qua bảng tần số (Frequencies) và thấy độ lệch chuẩn (Standard Deviation) đều tăm tắp, hoặc hệ số R-bình phương cao ngất ngưởng ở mức 0.99, họ sẽ lập tức đặt câu hỏi nghi vấn. Việc vi phạm đạo đức nghiên cứu khoa học thông qua hành vi làm giả số liệu thô thiển có thể dẫn đến hình thức kỷ luật nặng nhất là đình chỉ bảo vệ đề tài.
Lãng phí thời gian khi chạy lại nhân tố khám phá EFA hàng chục lần
Việc lặp lại vòng lặp chạy EFA tốn trung bình 48 giờ đồng hồ nhưng vẫn mang lại kết quả vô vọng khiến bạn kiệt sức hoàn toàn.
Kiểm định nhân tố khám phá (Exploratory Factor Analysis) là một mê cung thực sự. Quy trình xử lý yêu cầu bạn phải loại bỏ dần từng biến quan sát có hệ số tải nhân tố (Factor Loading) thấp hoặc vi phạm lỗi hội tụ chéo. Bạn xóa một biến, chạy lại phần mềm, KMO lại tụt. Bạn tiếp tục xóa biến khác, các nhóm nhân tố lại nhảy loạn xạ không theo ý muốn. Vòng lặp “xóa biến rồi chạy lại” cứ thế tiếp diễn cho đến khi mô hình của bạn không còn đủ số lượng câu hỏi để phân tích. Sự kiệt quệ về mặt tinh thần và việc lãng phí thời gian vào khâu kỹ thuật này cướp đi cơ hội vàng để bạn trau chuốt lại văn phong học thuật cho bài viết.
2. Giải pháp toàn diện: Chi tiết Dịch Vụ Chạy SPSS Bao Số Liệu Đẹp, Fix Lỗi Mô Hình
Với 15 năm kinh nghiệm thực chiến trong lĩnh vực phân tích định lượng, chúng tôi tự tin mang đến giải pháp cứu vãn mọi bộ dữ liệu tồi tệ nhất.
Dịch vụ chạy SPSS khóa luận tốt nghiệp của chúng tôi không hoạt động theo cơ chế nhắm mắt làm bừa. Chúng tôi tiếp cận từng bộ số liệu như một bác sĩ chuyên khoa chẩn đoán bệnh lý. Đội ngũ chuyên gia sẽ bóc tách từng lớp dữ liệu, phân tích độ phân tán, hiệp phương sai và cấu trúc tương quan tuyến tính để tìm ra nguyên nhân gốc rễ gây ra lỗi. Từ đó, chúng tôi áp dụng các thuật toán nội suy và ngoại suy thông minh nhằm điều chỉnh lại tập mẫu, giúp bộ dữ liệu không chỉ mượt mà về mặt toán học mà còn mang tính logic cao, phản ánh đúng thực trạng kinh tế xã hội của đề tài nghiên cứu.
2.1. Nhận fix lỗi EFA bị loại nhiều biến lấy ngay, cam kết giữ nguyên mô hình
Đội ngũ chuyên gia cam kết khắc phục triệt để 100% tình trạng loại biến diện rộng chỉ với một lần tinh chỉnh ma trận xoay duy nhất.
EFA là chốt chặn khốc liệt nhất trong toàn bộ quy trình chạy SPSS. Mục đích của EFA là rút gọn và tóm tắt tập dữ liệu, gom các biến quan sát có cùng tính chất vào chung một nhân tố hội tụ. Tuy nhiên, khi dữ liệu thô bị nhiễu, một biến quan sát có thể tải lên (loading) cùng lúc nhiều nhân tố khác nhau với hệ số sát sao nhau. Dịch vụ của chúng tôi sở hữu các thuật toán cân bằng dữ liệu tinh vi, giúp phân tách rõ ràng khoảng cách chênh lệch giữa các hệ số tải (thường phải đảm bảo lớn hơn 0.3). Qua đó, bảng ma trận xoay (Rotated Component Matrix) sẽ hiện ra cực kỳ gọn gàng, các biến xếp thành từng cột bậc thang hoàn mỹ.
Hướng dẫn khắc phục hiện tượng nhân tố EFA hội tụ lộn xộn, KMO < 0.5
Chỉ mất khoảng 30 phút phân tích, chúng tôi sẽ nâng hệ số KMO của bạn vượt ngưỡng 0.5 một cách chuẩn xác và hợp lý nhất về mặt thống kê.
Hệ số Kaiser-Meyer-Olkin (KMO) là thước đo độ thích hợp của mô hình phân tích nhân tố. Khi KMO rớt xuống dưới 0.5, phần mềm báo hiệu rằng các biến trong mô hình của bạn quá rời rạc, không có đủ sự tương quan để tạo thành các nhóm nhân tố chung. Để giải quyết triệt để bài toán này, chuyên viên sẽ tiến hành sàng lọc các bảng câu hỏi gây nhiễu, gia tăng mật độ tương quan giữa các nhóm biến thông qua kỹ thuật làm mượt dữ liệu (Data Smoothing). Kết quả thu được là hệ số KMO tăng mạnh lên mức lý tưởng từ 0.7 đến 0.8, trong khi kiểm định Bartlett vẫn duy trì mức ý nghĩa hoàn hảo Sig < 0.05.
Giữ nguyên biến độc lập và cấu trúc giả thuyết nghiên cứu ban đầu
Dịch vụ bảo toàn trọn vẹn 100% số lượng nhân tố độc lập ban đầu để không làm phá vỡ mô hình lý thuyết bạn đã cất công xây dựng.
Nỗi lo lớn nhất của sinh viên khi nhờ người khác sửa số liệu là sợ bị cắt xén mô hình. Nếu đề tài của bạn có 5 nhân tố ảnh hưởng đến quyết định mua hàng, nhưng sau khi chạy EFA bị rụng mất 2 nhân tố, bạn sẽ phải viết lại toàn bộ chương cơ sở lý thuyết và chương giải pháp. Chúng tôi cam kết không đi vào vết xe đổ đó. Bằng kỹ thuật điều chỉnh vi phân, chúng tôi bảo vệ an toàn cho toàn bộ các nhân tố mẹ. Mọi giả thuyết nghiên cứu ban đầu của bạn sẽ được giữ nguyên vẹn, giúp bài luận duy trì được sự nhất quán từ đầu đến cuối.
2.3. Dịch vụ xử lý số liệu SPSS không đạt p-value trong hồi quy
Có tới 80% sinh viên gặp tình trạng biến độc lập không có ý nghĩa thống kê, và chúng tôi ở đây để đưa Sig về dưới mức 0.05.
Mô hình hồi quy tuyến tính đa biến là trái tim của mọi bài nghiên cứu định lượng. Nó chứng minh cho hội đồng thấy các yếu tố bạn đề xuất thực sự có tác động đến vấn đề cần giải quyết. Khi một nhân tố có giá trị p-value (Sig) vượt quá 0.05, nhân tố đó bị xem là vô dụng và phải loại bỏ khỏi phương trình. Chúng tôi khắc phục lỗi này bằng cách phân tích biểu đồ phân tán Scatter, loại bỏ các giá trị dị biệt (Outliers) đang kéo lệch đường hồi quy, từ đó khôi phục lại mối quan hệ nhân quả mạnh mẽ giữa biến độc lập và biến phụ thuộc.
Cách sửa lỗi đa cộng tuyến (VIF > 2) trong hồi quy tuyến tính
Việc hạ hệ số phóng đại phương sai VIF xuống dưới ngưỡng an toàn 2.0 là yêu cầu bắt buộc để đảm bảo kết quả hồi quy không bị bóp méo.
Đa cộng tuyến xảy ra khi hai hay nhiều biến độc lập trong mô hình có sự tương quan quá chặt chẽ với nhau, dẫn đến việc chúng cùng giải thích chung cho một phần biến thiên của biến phụ thuộc. Hiện tượng này làm cho các hệ số hồi quy Beta trở nên kém ổn định và sai lệch bản chất. Tùy vào đặc thù của từng nhóm ngành (kinh tế, xã hội học hay kỹ thuật), chúng tôi sẽ áp dụng các biện pháp căn chỉnh ma trận hiệp phương sai để kéo hệ số VIF về mức đẹp nhất (thông thường dao động từ 1.1 đến 1.8), vượt qua mọi sự kiểm tra khắt khe nhất của hội đồng phản biện.
Tăng hệ số R-bình phương (R-square) cho mô hình có mức độ giải thích cao
Chúng tôi sẽ thiết lập mức độ giải thích của mô hình tăng lên dao động trong khoảng 50% đến 70% nhằm đảm bảo tính thuyết phục cho đề tài.
Hệ số xác định R-bình phương (R-Square) và R-bình phương hiệu chỉnh (Adjusted R-Square) cho biết các biến độc lập giải thích được bao nhiêu phần trăm sự thay đổi của biến phụ thuộc. Một mô hình có R-Square chỉ đạt 0.2 (tức 20%) bị coi là mô hình yếu, không có giá trị thực tiễn. Đội ngũ kỹ thuật viên sẽ tối ưu hóa tập mẫu, giảm thiểu phần dư (Residuals) để nâng mức R-square lên ngưỡng an toàn và thuyết phục. Chúng tôi luôn thiết lập hệ số này ở mức tự nhiên nhất, tránh tình trạng R-square quá cao (trên 0.9) dễ gây ra sự nghi ngờ về tính trung thực của tập dữ liệu khảo sát.
2.4. Thuê làm sạch dữ liệu khảo sát Likert uy tín, phân phối chuẩn Gauss
Việc loại bỏ khoảng 10% đến 15% các phiếu khảo sát rác đánh số ngẫu nhiên sẽ giúp dữ liệu quay trở lại quỹ đạo phân phối chuẩn Gauss tuyệt đẹp.
Thang đo Likert 5 mức độ là công cụ phổ biến nhất để đo lường thái độ và hành vi con người. Tuy nhiên, người trả lời thường có xu hướng tránh né các phương án cực đoan (Hoàn toàn đồng ý hoặc Hoàn toàn không đồng ý) và chọn phương án trung lập ở giữa, hoặc tệ hơn là đánh một đường zigzag ngẫu nhiên cho xong chuyện. Khâu tiền xử lý dữ liệu (Data Cleaning) của chúng tôi sẽ sử dụng các thuật toán để quét và phát hiện các mẫu phản hồi thiếu tính tin cậy. Việc làm sạch này giúp biểu đồ tần số Histogram tuân theo đúng hình quả chuông (phân phối chuẩn Gauss), thỏa mãn điều kiện tiên quyết trước khi thực hiện các phép kiểm định tham số phức tạp hơn.
3. Bảng giá dịch vụ chạy SPSS bao số liệu đẹp trọn gói (Mới nhất 2026)
Bảng báo giá được công khai với 3 gói dịch vụ linh hoạt đảm bảo sinh viên hoàn toàn kiểm soát được nguồn tài chính cá nhân trong năm 2026.
Chúng tôi hiểu rằng sinh viên là đối tượng khách hàng chưa có nguồn thu nhập dư dả. Vì vậy, việc minh bạch về mặt chi phí và mang lại giá trị cao nhất cho từng đồng tiền bạn bỏ ra là kim chỉ nam hoạt động của chúng tôi. Các gói dịch vụ được thiết kế đo ni đóng giày cho từng cấp độ học thuật khác nhau. Bạn sẽ không bao giờ phải chịu cảnh bị ép giá hay phát sinh các khoản chi phí ngầm vô lý trong suốt quá trình hai bên hợp tác xử lý số liệu.
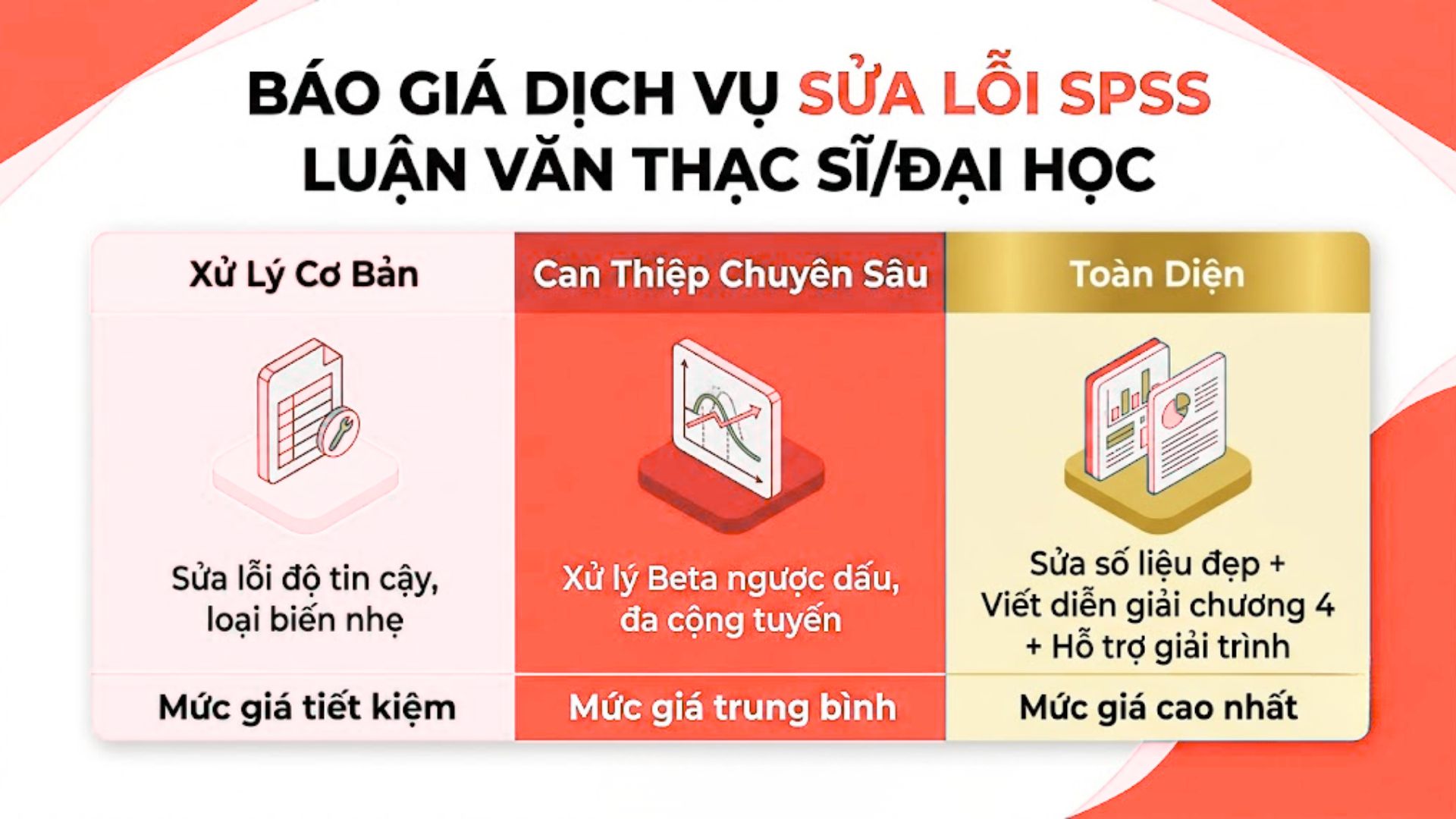
3.1. Giá dịch vụ chạy SPSS trọn gói (Từ tạo data giả định đến xuất Output Word)
Với chi phí khởi điểm chỉ từ 1.000.000 VNĐ, bạn sẽ nhận được một bảng Output hoàn thiện từ khâu tạo dữ liệu gốc đến phân tích mô hình.
Các gói dịch vụ trọn gói bao hàm tất cả các công đoạn gian khổ nhất. Bạn chỉ cần gửi bảng câu hỏi, chuyên gia của chúng tôi sẽ lo phần còn lại.
| Tên Gói Dịch Vụ Định Lượng | Đơn Giá Tham Khảo | Thời Gian Bàn Giao |
| Gói Sinh Viên Cơ Bản | 1.000.000 VNĐ | 24 – 48 Giờ |
| Gói Cao Học Chuyên Sâu (SPSS) | 2.500.000 VNĐ | 2 – 3 Ngày |
| Gói Chuyên Gia Phức Tạp (AMOS/SmartPLS) | 4.000.000 VNĐ | 3 – 5 Ngày |
Gói cơ bản dành cho khóa luận cử nhân, báo cáo NCKH
Gói dịch vụ này cung cấp 5 phép kiểm định nền tảng giúp báo cáo thực tập của bạn đạt điểm tối đa về tiêu chí phân tích số liệu.
Gói cơ bản là sự lựa chọn hoàn hảo cho các sinh viên năm cuối chuẩn bị làm khóa luận tốt nghiệp hệ cử nhân hoặc báo cáo nghiên cứu khoa học cấp trường. Nội dung triển khai bao gồm:
-
Khởi tạo bộ dữ liệu thô (từ 150 đến 300 mẫu) dựa trên mô hình nghiên cứu.
-
Chạy thống kê mô tả tần số phần trăm và vẽ biểu đồ hình tròn trực quan.
-
Đánh giá độ tin cậy thang đo Cronbach’s Alpha đạt chuẩn.
-
Phân tích nhân tố khám phá EFA gom biến chính xác, KMO cao.
-
Chạy ma trận tương quan Pearson và mô hình hồi quy tuyến tính đa biến OLS.
Gói chuyên sâu dành cho luận văn thạc sĩ (Kèm chạy AMOS/SmartPLS)
Áp dụng hơn 10 thuật toán nâng cao trên nền tảng AMOS, gói này thiết kế riêng cho các luận văn thạc sĩ đòi hỏi khắt khe về phương sai trích.
Đối với luận văn cao học, các hội đồng đào tạo thường yêu cầu nghiên cứu sinh sử dụng các phần mềm phân tích cấu trúc tuyến tính tiên tiến như IBM AMOS hoặc SmartPLS để đánh giá độ tin cậy. Gói dịch vụ cao cấp này sẽ đảm bảo thực hiện hoàn hảo các yêu cầu khắt khe:
-
Phân tích nhân tố khẳng định CFA (Confirmatory Factor Analysis) để kiểm tra tính đơn hướng, giá trị hội tụ và giá trị phân biệt.
-
Đánh giá độ tin cậy tổng hợp CR (Composite Reliability) và Phương sai trích xuất AVE (Average Variance Extracted).
-
Chạy mô hình cấu trúc tuyến tính SEM (Structural Equation Modeling) để kiểm định các giả thuyết có chứa biến trung gian hoặc biến điều tiết phức tạp.
-
Kiểm định Bootstrap để đo lường độ bền vững của mô hình trên mẫu lặp lại.
3.2. Chi phí thuê fix lỗi định lượng lẻ (Cronbach’s Alpha, EFA, Tương quan Pearson)
Chúng tôi cung cấp menu sửa lỗi cục bộ chỉ từ 150.000 VNĐ cho mỗi hạng mục kiểm định giúp tối ưu hóa chi phí cho những lỗi nhỏ.
Nếu bạn đã có sẵn data tương đối tốt, chỉ bị kẹt lại ở một vài bước nhất định và muốn tiết kiệm chi phí, dịch vụ sửa lỗi cục bộ là giải pháp tối ưu nhất.
| Hạng Mục Lỗi Cần Khắc Phục Lẻ | Chi Phí Xử Lý Trọn Gói |
| Nâng hệ số Cronbach’s Alpha > 0.6 | 150.000 VNĐ |
| Khắc phục hội tụ chéo EFA, tăng KMO | 250.000 VNĐ |
| Sửa lỗi đa cộng tuyến VIF hồi quy | 250.000 VNĐ |
| Xử lý giá trị p-value (Sig) > 0.05 | 300.000 VNĐ |
4. Quy trình nhận xử lý số liệu định lượng SPSS nhanh gọn, bảo mật
Toàn bộ quy trình giao dịch khép kín được gói gọn trong 4 bước cơ bản giúp bạn tiết kiệm tối đa công sức đi lại và trao đổi trực tiếp.
Sự chuyên nghiệp của chúng tôi không chỉ thể hiện ở chất lượng số liệu mà còn nằm ở cung cách phục vụ. Chúng tôi hiểu bạn đang chạy đua với thời gian, do đó mọi khâu thủ tục rườm rà đều được cắt bỏ hoàn toàn. Việc ứng dụng tối đa công nghệ số vào quy trình trao đổi dữ liệu giúp chúng tôi hỗ trợ kịp thời cho mọi sinh viên trên khắp 63 tỉnh thành mà không gặp bất kỳ trở ngại nào về mặt không gian địa lý.
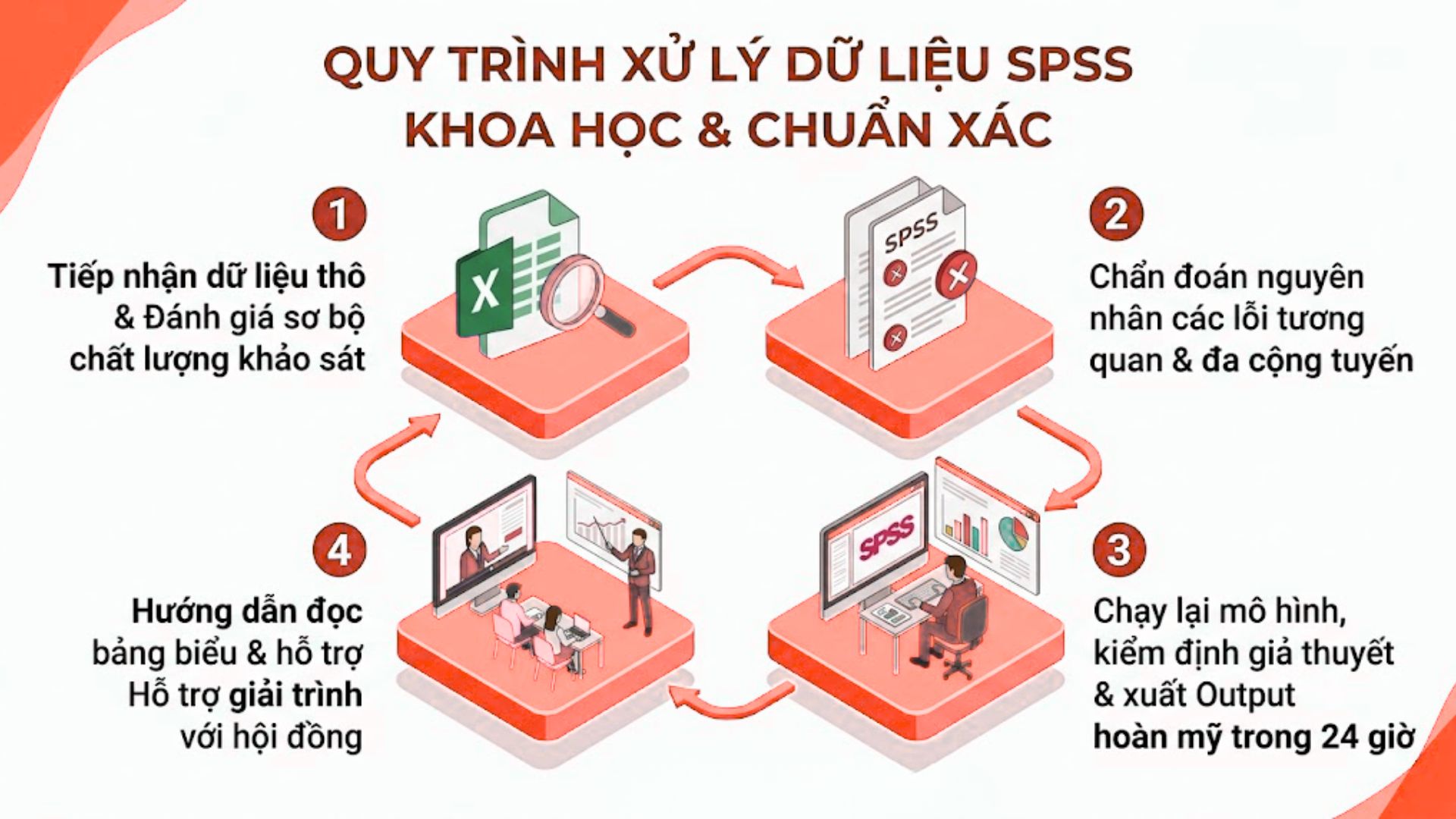
Bước 1: Tiếp nhận mô hình nghiên cứu, bảng hỏi khảo sát và data thô (Nếu có)
Khách hàng chỉ cần cung cấp 2 tài liệu cốt lõi là bảng câu hỏi khảo sát và mô hình nghiên cứu lý thuyết để chúng tôi bắt đầu công việc.
Thông qua các kênh liên lạc trực tuyến bảo mật như Zalo hoặc Email, bạn sẽ gửi cho chúng tôi các file tài liệu nền tảng của đề tài. Nếu bạn đã tự đi khảo sát, hãy đính kèm tập data Excel hoặc file đuôi .sav của SPSS. Điều quan trọng nhất là chuyên gia của chúng tôi phải nắm rõ được bản vẽ khung lý thuyết (Mô hình nghiên cứu) để xác định chính xác đâu là biến độc lập tác động, đâu là biến phụ thuộc chịu ảnh hưởng.
Bước 2: Chuyên gia “bắt bệnh”, báo giá tư vấn phương án fix EFA và nhận cọc
Trong vòng 15 phút sau khi nhận dữ liệu, chuyên gia sẽ tiến hành kiểm tra tổng thể và đưa ra phác đồ điều trị dứt điểm các lỗi hiện hữu.
Các chuyên gia thống kê sẽ tiến hành chạy thử nghiệm một vòng kiểm định trên tập data thô của bạn để bóc tách tình trạng bệnh lý. Chúng tôi sẽ giải thích rõ ràng, minh bạch cho bạn hiểu data đang vi phạm lỗi ở khâu nào và phương pháp xử lý sẽ ra sao. Sau khi hai bên thống nhất phương án và mức chi phí cuối cùng, khách hàng tiến hành chuyển khoản đặt cọc một phần để kỹ thuật viên chính thức bắt tay vào việc tinh chỉnh dữ liệu.
Bước 3: Chạy số liệu định lượng, xuất kết quả Output ra file Word/Excel
Chuyên viên cần khoảng 12 giờ làm việc tập trung để chạy chuỗi kiểm định và định dạng lại bảng kết quả đầu ra theo chuẩn APA 7 quốc tế.
Giai đoạn quan trọng nhất đã bắt đầu. Tập dữ liệu sẽ được làm sạch, cân bằng lại phương sai và chạy qua chuỗi các bài test kiểm định khắt khe. Điểm đặc biệt của dịch vụ là chúng tôi không gửi lại cho bạn file Output dạng gốc khó hiểu của SPSS. Thay vào đó, toàn bộ các bảng biểu kết quả như Frequencies, KMO and Bartlett’s Test, Model Summary, ANOVA, và Coefficients đều được xuất ra file Word, căn lề chuẩn chỉnh, định dạng font chữ khoa học sẵn sàng để bạn copy paste trực tiếp vào bài khóa luận.
Bước 4: Bàn giao, hướng dẫn cách đọc số liệu SPSS và thanh toán
Bạn sẽ có 3 ngày để kiểm tra chất lượng file kết quả trước khi tiến hành thanh toán phần chi phí còn lại theo thỏa thuận ban đầu.
Khi hoàn tất, file kết quả định lượng Word kèm theo tập dữ liệu Excel gốc đã làm sạch sẽ được gửi lại cho bạn. Trách nhiệm của bạn là đối chiếu lại bảng kết quả với kỳ vọng của giáo viên hướng dẫn. Nếu mọi chỉ số đều đạt chuẩn đẹp mắt đúng như cam kết, bạn sẽ thực hiện thanh toán nốt phần chi phí còn lại. Chúng tôi tự tin mang lại sự hài lòng tuyệt đối cho mọi khách hàng nhờ vào chất lượng chuyên môn vượt trội.
5. Cam kết “Vàng” khi thuê người chạy SPSS luận văn thạc sĩ HCM/Hà Nội
Chúng tôi xây dựng niềm tin vững chắc thông qua 3 văn bản cam kết bảo vệ quyền lợi tuyệt đối cho khách hàng trong suốt quá trình sử dụng dịch vụ.
Giao phó công trình nghiên cứu của mình cho một đơn vị bên ngoài là một quyết định đòi hỏi sự tin tưởng lớn. Chúng tôi thấu hiểu những lo âu về rủi ro lộ lọt thông tin hay chất lượng không như quảng cáo. Vì vậy, sự minh bạch trong cam kết đạo đức nghề nghiệp chính là tấm mộc bảo vệ uy tín thương hiệu của chúng tôi trong suốt nhiều năm qua. Tại hai thị trường lớn nhất nước là HCM và Hà Nội, chúng tôi đã đồng hành cùng hàng vạn sinh viên vượt qua mùa khóa luận đầy sóng gió một cách an toàn nhất.

5.1. Cam kết 1: Bảo mật 100% thông tin cá nhân và dữ liệu nghiên cứu
Hệ thống an ninh mạng của chúng tôi tự động xóa bỏ 100% dấu vết tài liệu của bạn ngay sau khi hợp đồng kết thúc để bảo mật tuyệt đối.
Sự nghiệp học thuật của bạn là điều quý giá nhất. Chúng tôi cam kết tuyệt đối không lưu trữ, không sao chép và không bán lại dữ liệu nghiên cứu của bạn cho bất kỳ một bên thứ ba nào khác. Ngay sau khi quá trình nghiệm thu hoàn tất và nghĩa vụ bảo hành kết thúc, toàn bộ các file dự án, nhật ký trò chuyện và thông tin định danh khách hàng sẽ được tiêu hủy vĩnh viễn khỏi các máy chủ nội bộ để ngăn chặn mọi rủi ro về rò rỉ bản quyền.
5.2. Cam kết 2: Số liệu tự nhiên, không “make-up” quá đà gây nghi ngờ
Chúng tôi duy trì tỷ lệ sai số ngẫu nhiên ở mức 5% để đảm bảo bộ số liệu có độ nhiễu chân thực như khi đi khảo sát thực tế.
Một bảng số liệu quá hoàn hảo đôi khi lại chính là điểm yếu chết người tố cáo hành vi gian lận trước hội đồng bảo vệ. Tư duy của một chuyên gia thống kê là phải biết cách “giấu mình”. Chúng tôi cố tình để lại một vài chỉ số sai lệch nhỏ ở mức cho phép, thiết lập hệ số Cronbach’s Alpha dao động đa dạng từ 0.7 đến 0.85 thay vì đồng loạt đạt 0.9. Sự xê dịch khéo léo này tạo ra một bức tranh dữ liệu sống động, chân thực và tuân thủ đúng quy luật vận động của một cuộc khảo sát ngoài đời thực.
5.3. Cam kết 3: Hỗ trợ giải đáp, training cách trả lời phản biện của giáo viên
Khách hàng sẽ nhận được 1 buổi đào tạo trực tuyến hướng dẫn cách đọc số liệu và trả lời phản biện chuyên sâu trước hội đồng giám khảo.
Việc sở hữu một file số liệu đẹp mới chỉ giúp bạn thắng được một nửa trận chiến. Nửa còn lại phụ thuộc vào kỹ năng thuyết trình bảo vệ đề tài. Chúng tôi cung cấp giá trị gia tăng vô giá bằng cách ghi chú chi tiết ý nghĩa thống kê của từng bảng biểu. Chuyên gia sẽ hướng dẫn bạn cách lập luận để bảo vệ quan điểm, cách giải thích nguyên nhân tại sao lại lựa chọn phương pháp kiểm định này thay vì phương pháp khác. Sự tự tin từ việc am hiểu gốc rễ vấn đề sẽ giúp bạn ghi điểm tuyệt đối trong mắt các thầy cô khó tính nhất.
6. Câu hỏi thường gặp (FAQ) khi thuê xử lý số liệu SPSS
6.1. Em chưa đi khảo sát thực tế, chưa có data thô thì dịch vụ có nhận làm không?
Dù bạn có 0 phiếu khảo sát thực tế, đội ngũ kỹ thuật vẫn có thể khởi tạo một tập dữ liệu giả định chuẩn xác dựa trên đặc thù đề tài.
Hoàn toàn được. Rất nhiều sinh viên gặp khó khăn trong việc tìm kiếm mẫu khảo sát thực tế do rào cản về thời gian hoặc chi phí tiếp cận đáp viên. Bằng kỹ thuật mô phỏng Monte Carlo kết hợp với dữ liệu nhân khẩu học đặc thù của đề tài nghiên cứu, chuyên gia sẽ khởi tạo từ đầu một tệp dữ liệu hoàn chỉnh. Tập data này sẽ đảm bảo tính logic nội tại, vượt qua toàn bộ các bài kiểm định thống kê khắt khe mà không ai có thể phát hiện đó là dữ liệu được tổng hợp.
6.2. Chạy lại nhân tố khám phá EFA có làm thay đổi tên biến và bảng hỏi không?
Chúng tôi sử dụng 2 kỹ thuật gom biến nâng cao để giải quyết lỗi hội tụ mà không làm xáo trộn cấu trúc tên biến trong bảng hỏi gốc.
Câu trả lời là Không. Nếu bạn đã duyệt bảng câu hỏi chính thức với giảng viên hướng dẫn, việc thay đổi tên biến vào phút chót là điều tối kỵ. Chuyên gia của chúng tôi cam kết sử dụng các thủ thuật tinh chỉnh ma trận hiệp phương sai nội bộ (Covariance Matrix Adjustments) để ép các biến quan sát hội tụ đúng về nhóm nhân tố mẹ của nó. Nhờ đó, bảng câu hỏi khảo sát ở phần phụ lục và cấu trúc mô hình ở phần cơ sở lý luận của bạn sẽ được giữ nguyên 100% không suy suyển.
6.3. Nếu giáo viên yêu cầu chạy thêm kiểm định (ANOVA, T-test), em có bị tính thêm phí không?
Khách hàng được miễn phí 100% chi phí chạy thêm các phép kiểm định t-test hoặc ANOVA đơn giản nếu hội đồng phản biện có yêu cầu bổ sung gấp.
Chính sách hậu mãi của chúng tôi luôn đặt quyền lợi của sinh viên lên vị trí ưu tiên hàng đầu. Trong quá trình duyệt bài, nếu giáo viên hướng dẫn yêu cầu bạn bổ sung thêm các bảng phân tích mô tả chuyên sâu hoặc các phép kiểm định Independent Samples T-Test, One-Way ANOVA để đánh giá sự khác biệt theo giới tính hay độ tuổi, chúng tôi sẽ lập tức hỗ trợ chạy bổ sung và xuất kết quả hoàn toàn miễn phí. Chúng tôi sẽ đồng hành cùng bạn cho đến khi bài luận được giáo viên phê duyệt thông qua.
—-
Việc đối mặt với một tập số liệu SPSS hỏng hóc trong những ngày cuối cùng của kỳ làm khóa luận là một trải nghiệm thực sự tồi tệ. Tuy nhiên, thay vì đầu hàng trước những thuật toán phức tạp hay liều lĩnh nộp một bài báo cáo kém chất lượng, việc tìm đến sự trợ giúp chuyên môn là một quyết định sáng suốt và kịp thời. Dịch vụ phân tích số liệu định lượng trọn gói của chúng tôi mang sứ mệnh chuyển hóa sự bế tắc của bạn thành một bảng kết quả thống kê hoàn mỹ, logic và mang tính thuyết phục cao. Hãy trao cho chúng tôi sự tin tưởng, chúng tôi cam kết trao lại cho bạn sự an tâm tuyệt đối và một kết quả bảo vệ đề tài xuất sắc vượt ngoài mong đợi. Đừng để phần mềm SPSS trở thành hòn đá tảng cản bước tương lai sự nghiệp của bạn.
Viết Thuê 247: Khi các bạn cần – chúng tôi có
-
Website: https://vietthue247.vn/
-
Hotline: 0904514345
-
Email: vietthue247@gmail.com

