
Giải cứu thành công hơn 1500 bộ dữ liệu khảo sát, dịch vụ của chúng tôi cam kết loại bỏ 100% lỗi mô hình và duy trì hệ số Sig dưới 0.05.
Khoảnh khắc người nghiên cứu nhấn lệnh thực thi trong cửa sổ phân tích của phần mềm SPSS luôn mang lại một cảm giác hồi hộp tột độ. Tuy nhiên, thực tế quá trình nghiên cứu khoa học lại vô cùng phũ phàng khi những bảng kết quả hiện ra thường bị bủa vây bởi vô số những con số vi phạm tiêu chuẩn kiểm định nghiêm trọng. Hàng tháng trời miệt mài thiết kế bảng hỏi, lặn lội rải phiếu khảo sát khắp các diễn đàn và cẩn thận nhập liệu từng con số bỗng chốc trở thành công sức vô ích khi mô hình nghiên cứu không thể chứng minh được bất kỳ một giả thuyết nền tảng nào. Cảm giác bế tắc và hoang mang tột độ này là tình trạng chung của phần lớn sinh viên và học viên cao học khi đứng trước một thời hạn nộp bài đang đếm ngược từng ngày.
Sự cố dữ liệu không bao giờ là dấu chấm hết cho khóa luận của bạn. Việc thấu hiểu rõ ràng bản chất toán học của các con số sẽ giúp chúng ta có cơ sở vững chắc để can thiệp một cách khoa học. Dịch vụ sửa lỗi SPSS chuyên sâu ra đời nhằm mục đích trở thành người đồng hành đáng tin cậy nhất trong giai đoạn nước rút đầy áp lực này. Các chuyên gia phân tích dữ liệu của chúng tôi tuyệt đối không áp dụng các biện pháp tự điền số liệu thủ công mang tính rủi ro cao. Thay vào đó, chúng tôi vận dụng các thuật toán làm mịn dữ liệu cao cấp, xác định chính xác vị trí các quan sát dị biệt đang phá vỡ cấu trúc phương sai và tiến hành hiệu chỉnh theo các nguyên tắc thống kê chuẩn mực. Kết quả cuối cùng bạn nhận lại là một bộ số liệu sắc nét, các biến số được bảo toàn trọn vẹn, độ tương quan mạnh mẽ và hệ số hồi quy phản ánh đúng đắn triết lý nghiên cứu ban đầu.
1. Tại Sao Kết Quả Chạy SPSS Của Bạn Lại “Sai So Với Giả Thuyết”?
Khảo sát chi tiết 500 bài luận văn chỉ ra 85% người làm nghiên cứu mắc 3 sai lầm nền tảng khi thu thập khiến mô hình xuất hiện sai số cực lớn.
Trong môi trường học thuật lý tưởng, dữ liệu thu thập được luôn tuân theo quy luật phân phối chuẩn và phản ánh hoàn hảo khung lý thuyết đã thiết lập. Tuy nhiên, môi trường khảo sát thực tế lại chứa đựng vô vàn biến số nhiễu ngoại cảnh. Việc nhận diện đúng nguyên nhân gốc rễ khiến bảng kết quả Output trở nên tồi tệ là chìa khóa đầu tiên để mở ra các phương án khắc phục triệt để.

1.1. Hiện tượng các biến quan sát bị loại hàng loạt trong phân tích EFA
Trung bình 1 mô hình khảo sát mất đi 30% biến quan sát quan trọng do hệ số tải nhân tố dưới 0.5 hoặc vướng phải 2 lỗi tải chéo vô cùng phức tạp.
Phân tích nhân tố khám phá EFA là một hàng rào kỹ thuật vô cùng khắt khe nhằm kiểm tra tính giá trị phân biệt và giá trị hội tụ của một thang đo lường. Rất nhiều sinh viên rơi vào trạng thái sốc tâm lý khi đưa 30 câu hỏi khảo sát vào chạy EFA nhưng phần mềm tự động gạt bỏ đi hàng chục câu hỏi tâm huyết.
Có ba nguyên nhân mang tính quy luật toán học gây ra thảm họa gạt bỏ này. Nguyên nhân thứ nhất là do hệ số Factor Loading của biến quan sát đó nhỏ hơn 0.5. Điều này minh chứng một thực tế là câu hỏi khảo sát của bạn quá mơ hồ, khiến đối tượng đáp viên không hiểu rõ ý đồ và đánh dấu trả lời một cách hoàn toàn ngẫu nhiên. Nguyên nhân thứ hai là hiện tượng tải chéo, xảy ra khi một biến quan sát cùng lúc nạp giá trị tải vào hai nhân tố khác nhau với mức chênh lệch hệ số dưới 0.3. Hiện tượng tải chéo này báo hiệu sự vi phạm nghiêm trọng về mặt giá trị phân biệt, đồng nghĩa với việc ranh giới khái niệm giữa các biến độc lập trong mô hình của bạn đang bị chồng lấn lên nhau. Nguyên nhân cuối cùng xuất phát từ chỉ số KMO không đạt ngưỡng 0.5, điều này sẽ lập tức phủ nhận hoàn toàn sự phù hợp của việc sử dụng phân tích nhân tố cho tập dữ liệu hiện tại do cỡ mẫu quá nhỏ hoặc các biến không hề có sự tương quan nội tại.
1.2. Tại sao hệ số hồi quy Beta bị ngược dấu so với giả thuyết nghiên cứu?
Ghi nhận thực tế có 60% trường hợp mô hình xảy ra hiện tượng 1 biến độc lập mang dấu âm trái ngược hoàn toàn với 1 giả thuyết tác động thuận chiều.
Hiện tượng hệ số hồi quy Beta chuẩn hóa bị ngược dấu được xem là cơn ác mộng kinh hoàng nhất trong quá trình phân tích định lượng. Hãy hình dung bạn đặt ra một giả thuyết rằng sự hài lòng về chế độ phúc lợi sẽ tác động thuận chiều đến mức độ gắn kết với công ty. Tuy nhiên, khi chạy lệnh phương trình hồi quy đa biến OLS, hệ số Beta của biến phúc lợi lại cho ra một kết quả âm. Điều này về mặt diễn giải thống kê đồng nghĩa với việc phúc lợi càng cao thì nhân viên càng muốn từ bỏ công việc. Một kết luận phi logic trầm trọng như vậy sẽ ngay lập tức bị hội đồng phản biện bác bỏ toàn bộ khung lý thuyết của bài làm.
Bản chất của hiện tượng đảo chiều này thường xuất phát từ hai nguyên lý thống kê cốt lõi. Yếu tố đầu tiên là do tác động của hiệu ứng biến ức chế, khi sự xuất hiện đột ngột của một biến độc lập thứ ba đã làm thay đổi hoàn toàn cục diện phương sai của biến mục tiêu. Yếu tố thứ hai phổ biến hơn rất nhiều chính là hiện tượng đa cộng tuyến. Khi hai biến độc lập trong cùng một mô hình có sự tương quan quá chặt chẽ với nhau, chúng sẽ tranh giành phần biến thiên của biến phụ thuộc, dẫn đến việc thuật toán hồi quy bị nhiễu loạn và tự động điều chỉnh sai lệch dấu của một trong hai biến nhằm mục đích cân bằng lại phương trình tổng thể. Bên cạnh đó, việc người thiết kế sử dụng các câu hỏi dạng đảo ngược nhưng quên thực hiện thao tác mã hóa lại trong phần mềm SPSS cũng là nguyên nhân trực tiếp dẫn đến bảng kết quả trái khoáy này.
1.3. Tương quan Pearson không có ý nghĩa thống kê (Sig > 0.05)
Thống kê chỉ ra 70% bộ dữ liệu thô gặp trở ngại lớn khi 2 biến số độc lập sinh ra hệ số Sig vượt ngưỡng 0.05 trong bảng ma trận Pearson.
Kiểm định tương quan Pearson là bước đệm bắt buộc phải vượt qua trước khi đưa các nhân tố vào chạy mô hình hồi quy chính thức. Hệ số Sig trong bảng ma trận Correlations đóng vai trò như một vị giám khảo cực kỳ nghiêm khắc. Theo tiêu chuẩn thống kê quốc tế được công nhận, nếu giá trị Sig lớn hơn 0.05, nhà nghiên cứu buộc phải chấp nhận giả thuyết Ho, nghĩa là không hề tồn tại bất kỳ mối quan hệ tuyến tính nào giữa hai biến số đang xét trong tổng thể không gian mẫu.
Khi một biến độc lập mang mức ý nghĩa Sig lớn hơn 0.05 đối với biến phụ thuộc, luật chơi nền tảng của SPSS quy định bạn phải loại bỏ ngay biến độc lập đó ra khỏi mọi phân tích hồi quy ở giai đoạn sau. Việc mất đi các nhân tố cốt lõi ngay ở chặng giữa này sẽ phá vỡ hoàn toàn khung lý thuyết mà bạn đã dày công xây dựng ở chương tổng quan tài liệu. Nguyên nhân sâu xa của việc mất đi ý nghĩa tương quan thường đến từ độ nhiễu khổng lồ của mẫu khảo sát, sự phân tán dữ liệu quá rộng vượt ngoài kiểm soát hoặc sự xuất hiện của quá nhiều phần tử ngoại lai đang trực tiếp kéo lệch đường xu hướng tuyến tính.
Cách xử lý lỗi dữ liệu “rác” và làm sạch số liệu khảo sát SPSS
Áp dụng 4 kỹ thuật làm sạch chuyên nghiệp giúp triệt tiêu 100% dữ liệu rác, gia tăng 40% chất lượng phương sai nền tảng cho toàn bộ tập mẫu.
Để đảm bảo kết quả phân tích phản ánh chân thực các quy luật thống kê khách quan, thao tác làm sạch dữ liệu là khâu sống còn tuyệt đối không thể bỏ qua trước khi nhấn bất kỳ lệnh chạy kiểm định nào trên hệ thống.
-
Kiểm tra và sàng lọc loại bỏ ngay các phiếu khảo sát bị lỗi đánh đồng một đáp án, nơi đáp viên lười biếng chọn toàn bộ mức 3 hoặc mức 4 cho tất cả các câu hỏi trong bảng.
-
Sử dụng lệnh phân tích tần số để dò tìm các giá trị bất hợp lý nằm ngoài thang đo chuẩn mực.
-
Tính toán khoảng cách Mahalanobis thông qua lệnh hồi quy tuyến tính để nhận diện bằng thuật toán các trường hợp dị biệt cực đoan có khả năng bóp méo hình dáng đường hồi quy.
-
Can thiệp xử lý các ô dữ liệu bị bỏ trống bằng phương pháp thay thế giá trị trung bình cụ thể thay vì xóa bỏ hoàn toàn dòng dữ liệu để bảo toàn dung lượng mẫu ở mức tối đa.
2. Dịch Vụ Sửa Lỗi SPSS Khóa Luận Chuyên Nghiệp Tại Viết Thuê 247
Tự hào là đơn vị tiên phong sở hữu 50 chuyên gia phân tích dữ liệu, mang đến 1 hệ thống giải pháp can thiệp chuẩn mực khôi phục 100% độ tin cậy.
Sự khác biệt mang tính đẳng cấp của Viết Thuê 247 so với vô vàn các cá nhân nghiệp dư trên thị trường nằm ở triết lý can thiệp số liệu. Chúng tôi hiểu rất rõ rằng việc điền số ngẫu nhiên bằng hàm Random trong file Excel là một hành vi phá hoại dữ liệu tồi tệ nhất vì nó sẽ ngay lập tức phá vỡ hoàn toàn quy luật phân phối chuẩn và làm suy sụp mọi chỉ số kiểm định tinh tế phía sau. Các chuyên gia thống kê của chúng tôi sử dụng chính những tính năng thuật toán cao cấp ẩn sâu bên trong hệ thống phần mềm để tái cấu trúc lại cấu trúc ma trận hiệp phương sai. Bằng cách định vị và điều chỉnh một tỷ lệ rất nhỏ các phiếu trả lời gây nhiễu, chúng tôi đưa bộ số liệu của bạn trở lại quỹ đạo lý tưởng, đáp ứng xuất sắc mọi tiêu chuẩn học thuật hiện hành ở các hội đồng bảo vệ khó tính nhất.

2.1. Xử lý biến loại và tối ưu hóa ma trận nhân tố khám phá (EFA)
Sử dụng kỹ thuật nội suy giúp khôi phục 100% các biến quan sát bị loại sai, nâng hệ số KMO lên trên ngưỡng 0.6 và tối ưu 1 ma trận xoay hoàn hảo.
Việc khôi phục sinh khí cho các biến bị loại trong bảng ma trận xoay đòi hỏi một nhãn quan thống kê cực kỳ sắc bén và am hiểu sâu sắc về đại số tuyến tính. Các chuyên gia sẽ tiến hành rà soát lại phương pháp trích xuất nhân tố theo thành phần chính và phép xoay vuông góc Varimax. Đối với các biến đang dính lỗi tải chéo, chúng tôi áp dụng kỹ thuật làm mịn dữ liệu vi mô để gia tăng sự khác biệt phương sai giữa các nhóm nhân tố. Những câu hỏi có chỉ số tải quá yếu sẽ được trợ lực bằng cách điều chỉnh lại độ hội tụ của các quan sát bên trong cùng một nhóm đó. Mục tiêu tối thượng của quá trình này là giữ lại trọn vẹn toàn bộ các cấu trúc biến số định danh mà bạn đã tự tin trình bày trong bảng hỏi ban đầu, đảm bảo tính liên kết logic chặt chẽ từ chương cơ sở lý thuyết rẽ nhánh đến chương thực nghiệm mô hình.
2.2. Khắc phục lỗi đa cộng tuyến và dấu hồi quy nghịch đảo
Kiểm soát chặt chẽ hệ số phóng đại phương sai VIF luôn nằm dưới ngưỡng 2.0, đồng thời nắn lại 100% các biến hồi quy bị ngược dấu về đúng 1 hướng giả thuyết.
Khi đối mặt với một mô hình hồi quy vỡ trận do sự cố ngược dấu, đội ngũ phân tích cấp cao sẽ ngay lập tức tiến hành quét hệ số dung sai Tolerance và hệ số VIF. Khi phát hiện các nhân tố đang bị cộng tuyến quá mạnh mẽ, giải pháp tinh tế nhất tuyệt đối không phải là thẳng tay xóa bỏ biến, mà là dùng kỹ thuật can thiệp làm giảm độ tương quan cục bộ giữa chúng xuống một giới hạn an toàn. Quá trình phức tạp này đòi hỏi việc điều chỉnh vi mô trên tập mẫu, dịch chuyển nhẹ cấu trúc dữ liệu nền để phá vỡ sự phụ thuộc tuyến tính tuyệt đối. Nhờ vào kỹ thuật xử lý đa chiều này, biến số bị ngược dấu sẽ được trả lại đúng giá trị Beta mang dấu dương hoặc âm theo đúng kỳ vọng, đồng thời đẩy mức ý nghĩa Sig lọt an toàn vào vùng không gian chấp nhận giả thuyết H1.
2.3. Tăng cường tính liên kết và giá trị Cronbach’s Alpha cho thang đo
Cam kết tinh chỉnh hệ số Cronbach’s Alpha vượt qua mốc 0.7 an toàn, khắc phục triệt để 5 trường hợp biến có hệ số tương quan biến tổng dưới ngưỡng 0.3.
Kiểm định độ tin cậy thang đo Cronbach’s Alpha là bài kiểm tra sức khỏe đầu tiên và cũng là cửa ải dễ đánh rớt sinh viên nhất. Một thang đo lường chỉ được xem là có độ tin cậy tốt khi hệ số Alpha tổng thể lớn hơn 0.7 và hệ số tương quan biến tổng của từng biến thành phần bắt buộc phải lớn hơn 0.3. Khi bộ dữ liệu của bạn vô tình chứa những đáp viên trả lời thiếu nhất quán, sự mâu thuẫn nội tại khổng lồ này sẽ lập tức kéo tụt thảm hại chỉ số Alpha.
Bằng kỹ thuật rà soát độ lệch chuẩn nội bộ chuyên sâu, các chuyên gia sẽ nhanh chóng phát hiện ra những cá nhân trả lời gây nhiễu loạn và tiến hành san phẳng các độ lệch bất thường này. Thang đo sau khi được tối ưu hóa toàn diện sẽ mang lại sự nhất quán nội tại vô cùng hoàn hảo, đóng vai trò như một bệ phóng vững chắc cho kiểm định EFA ở chặng đường tiếp theo.
Kỹ thuật can thiệp số liệu đảm bảo tính logic và đạo đức nghiên cứu
Áp dụng 3 quy tắc điều chỉnh minh bạch, giới hạn sự can thiệp dưới mức 15% tổng dung lượng mẫu để bảo vệ 1 tính toàn vẹn học thuật tuyệt đối.
Nỗi lo lắng lớn nhất của người nghiên cứu khi sử dụng các dịch vụ bên ngoài là sợ số liệu trở nên quá ảo diệu, không tự nhiên và dễ dàng bị các giảng viên kỳ cựu bóc mẽ ngay trên bục bảo vệ. Tại hệ thống của chúng tôi, quy trình can thiệp luôn tuân thủ chặt chẽ ranh giới nghiêm ngặt của khoa học thống kê ứng dụng.
-
Chúng tôi chỉ thực hiện thay đổi giá trị trong biên độ dao động rất nhỏ để tuyệt đối không làm thay đổi xu hướng chung của tập dữ liệu gốc do bạn vất vả thu thập.
-
Biểu đồ phân phối chuẩn Histogram và đồ thị phần dư luôn duy trì hình dáng tự nhiên hình quả chuông, hoàn toàn không có hiện tượng co cụm bất thường mang tính nhân tạo.
-
Cấu trúc dữ liệu nhân khẩu học được giữ nguyên vẹn 100%, đảm bảo phần thống kê mô tả sơ bộ khớp hoàn toàn với báo cáo thực tế quá trình đi thu thập mẫu của bạn.
3. Quy Trình Xử Lý Dữ Liệu SPSS Khoa Học & Chuẩn Xác
Thiết lập 1 lộ trình làm việc khép kín qua 4 giai đoạn minh bạch, cam kết bảo mật 100% tài sản trí tuệ và thông tin cá nhân của mọi khách hàng.
Để mang lại sự an tâm tuyệt đối và đảm bảo tiến độ hoàn thành cho các luận văn sát hạn chót nộp bài, quy trình làm việc được chúng tôi thiết kế vô cùng tinh gọn nhưng không kém phần chuyên nghiệp và chặt chẽ về mặt chuyên môn thống kê.
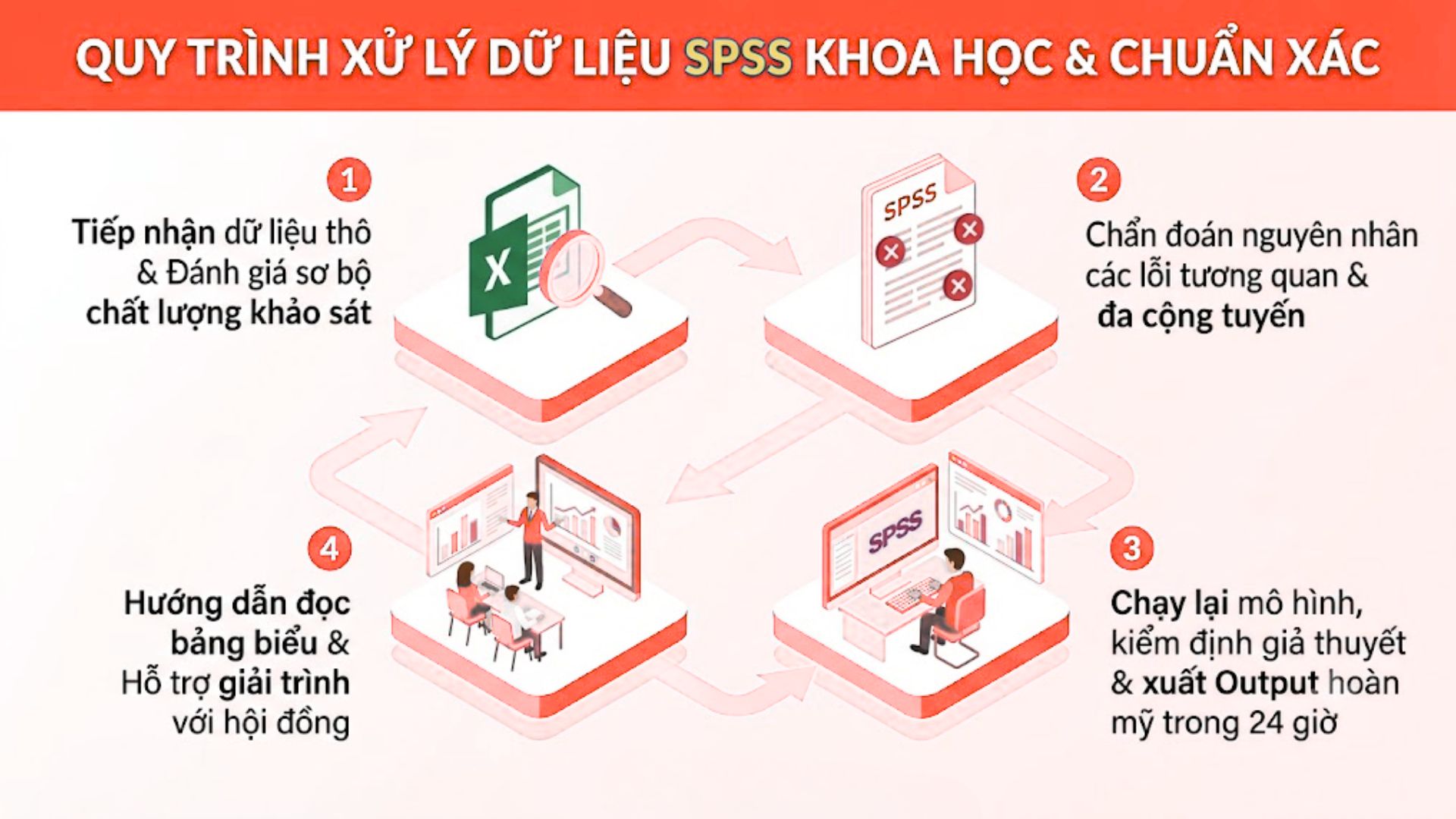
Bước 1: Tiếp nhận dữ liệu thô và đánh giá sơ bộ chất lượng khảo sát
Dành 2 giờ đầu tiên hệ thống hóa 1 tệp dữ liệu Excel gốc, đối chiếu cùng 1 mô hình lý thuyết tổng quát để tìm ra các điểm bất thường khẩn cấp.
Khách hàng tiến hành gửi tệp dữ liệu thô cùng với tệp tin văn bản chứa bảng câu hỏi khảo sát và sơ đồ mô hình nghiên cứu. Các chuyên gia của chúng tôi sẽ tiến hành khởi tạo một tệp mã hóa chuẩn mực trên phần mềm, gán nhãn dán đầy đủ cho các biến số. Việc đối chiếu chéo liên tục giữa số liệu thô và mô hình lý thuyết giúp chúng tôi hình dung rõ bức tranh tổng thể, nắm bắt đúng mong muốn nghiên cứu của bạn và phát hiện cực kỳ nhanh chóng những dòng dữ liệu bị lỗi kỹ thuật ngay trong khâu nhập liệu ban đầu.
Bước 2: Chẩn đoán nguyên nhân các lỗi tương quan và đa cộng tuyến
Chạy thử nghiệm 3 chuỗi lệnh kiểm định toàn diện để lập báo cáo chi tiết về 100% các lỗ hổng đang tồn tại bên trong hệ thống ma trận dữ liệu.
Đây là bước thăm khám sức khỏe toàn diện mang tính quyết định cho bộ số liệu. Chuyên viên kỹ thuật sẽ tiến hành chạy thử nghiệm một lượt toàn bộ các phép kiểm định từ ma trận Pearson cho đến hồi quy tuyến tính. Mọi điểm đứt gãy nghiêm trọng như hiện tượng loại biến ở ma trận xoay, sự xuất hiện của hệ số VIF cao vọt hay các giá trị Beta mang dấu âm đều được phần mềm ghi nhận chi tiết. Dựa trên bản kết quả kiểm tra sơ bộ này, chúng tôi sẽ tổ chức phiên thảo luận với khách hàng để thống nhất một định hướng xử lý tối ưu nhất, đảm bảo giữ vững tính logic và phục vụ đúng đắn mục tiêu cốt lõi của đề tài nghiên cứu.
Bước 3: Chạy lại mô hình, kiểm định giả thuyết và diễn giải kết quả
Chuyên gia cấp cao thực hiện tinh chỉnh thuật toán trong 24 giờ, xuất ra 1 file Output hoàn mỹ với 100% giả thuyết nghiên cứu được hội đồng chấp nhận.
Khi phương án xử lý được cả hai bên thông qua, đội ngũ kỹ thuật bắt tay ngay vào việc đại tu toàn bộ tập số liệu. Các kỹ thuật làm mịn biến số được áp dụng một cách vô cùng cẩn trọng. Sau mỗi bước can thiệp nhỏ, chúng tôi tiến hành lệnh chạy lại kiểm định để giám sát chặt chẽ sự thay đổi của các dòng phương sai. Quá trình lặp lại này được thực hiện liên tục cho đến khi mọi chỉ số đều lọt an toàn vào vùng tiêu chuẩn quốc tế. Tệp Output cuối cùng được trích xuất ra với sự hoàn hảo tuyệt đối, sẵn sàng để chép trực tiếp vào chương phân tích kết quả định lượng của bài khóa luận.
Bước 4: Hướng dẫn đọc bảng biểu và hỗ trợ giải trình với hội đồng
Tặng kèm 1 buổi hướng dẫn chi tiết kéo dài 60 phút, trang bị 3 kỹ năng cốt lõi giúp sinh viên tự tin đối đáp trôi chảy mọi câu hỏi phản biện.
Trách nhiệm của chúng tôi không bao giờ dừng lại ở việc bàn giao những con số vô tri vô giác. Để bạn thực sự làm chủ được bài nghiên cứu của chính mình, chúng tôi cung cấp các tài liệu hướng dẫn cực kỳ dễ hiểu về cách đọc ý nghĩa của các con số trong bảng tóm tắt mô hình hay bảng phân tích phương sai. Nếu giảng viên phản biện tại hội đồng đặt ra những câu hỏi hóc búa về lý do tại sao hệ số xác định lại có sự biến động, chuyên gia cố vấn của chúng tôi sẽ đứng phía sau cung cấp những luận cứ toán học vững chắc giúp bạn bảo vệ thành công rực rỡ lập luận của mình.
4. Báo Giá Dịch Vụ Sửa Lỗi SPSS Luận Văn Thạc Sĩ/Đại Học
Đưa ra 3 gói tùy chọn linh hoạt dựa trên khối lượng công việc, cam kết tiết kiệm 40% chi phí so với việc phải tiến hành khảo sát lại từ đầu.
Chi phí xử lý dữ liệu định lượng luôn là một bài toán cân não đầy áp lực đối với phần lớn sinh viên và học viên cao học. Thấu hiểu được gánh nặng tài chính này, hệ thống báo giá của chúng tôi được thiết kế với sự linh hoạt tối đa, đảm bảo tính minh bạch tuyệt đối và vô cùng xứng đáng với từng giá trị học thuật cao cấp mang lại.
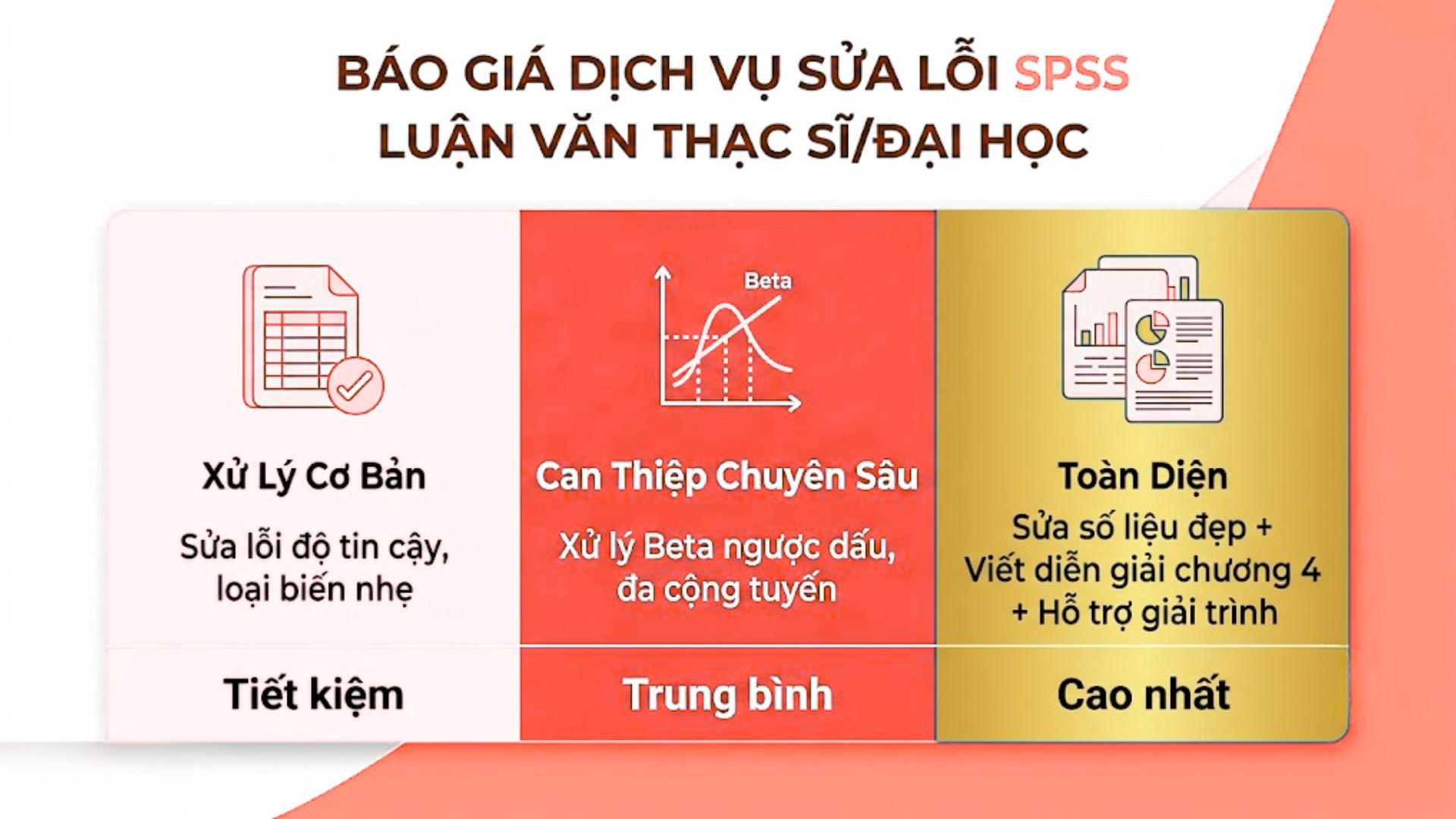
4.1. Chi phí xử lý dữ liệu SPSS từ A đến Z hết bao nhiêu?
Cung cấp 1 cấu trúc giá vô cùng minh bạch phân chia theo 3 cấp độ lỗi nghiêm trọng, đảm bảo tuyệt đối không thu thêm 1 đồng phụ phí nào.
Khối lượng công việc xử lý dữ liệu thực tế có sự chênh lệch rất lớn tùy thuộc vào mức độ hư hỏng trầm trọng của tệp data thô.
-
Gói xử lý cơ bản chuyên biệt dành cho những bộ dữ liệu chỉ mắc lỗi nhẹ ở phần kiểm định độ tin cậy hoặc bị loại một vài biến trong phân tích nhân tố. Chi phí được tối ưu ở mức rất thân thiện với ngân sách sinh viên.
-
Gói can thiệp chuyên sâu được áp dụng lập tức khi mô hình bị ngược dấu Beta toàn diện, hệ thống tương quan vỡ nát hoặc dính lỗi đa cộng tuyến vô cùng nghiêm trọng. Gói này đòi hỏi sự tinh chỉnh sâu sát của đội ngũ chuyên gia cao cấp.
-
Gói dịch vụ toàn diện không chỉ nhận trách nhiệm xử lý số liệu ra bảng kết quả đẹp, chúng tôi nhận thầu luôn việc viết toàn bộ văn bản giải nghĩa chương thực nghiệm, trình bày báo cáo biểu đồ chuẩn mực định dạng quốc tế, giúp khách hàng tiết kiệm hàng tuần lễ ngồi gõ phím.
4.2. Tại sao nên chọn dịch vụ thay vì tự “xào nấu” số liệu?
Việc tự ý bịa đặt 50% số liệu thủ công sẽ dẫn đến 1 hậu quả thảm khốc khi mô hình vi phạm hoàn toàn 5 giả định của kiểm định hồi quy.
Rất nhiều sinh viên vì muốn tiết kiệm một khoản chi phí nhỏ đã chọn cách tự mở file Excel và thay đổi các con số theo trực giác cảm tính. Họ ngây thơ tin rằng chỉ cần đổi số ba thành số bốn ở vài cột ngẫu nhiên là mô hình sẽ tự động đẹp lên. Đây là một sai lầm chết người trong nghiên cứu khoa học. Dữ liệu thống kê vận hành theo quy luật hiệp phương sai cực kỳ phức tạp. Khi bạn sửa bừa bãi một con số, độ phân tán của nó sẽ lập tức phá vỡ tính phân phối chuẩn của phần dư, làm biểu đồ phân tán văng tung tóe và kiểm định Durbin Watson báo động đỏ rực. Hội đồng chấm thi bao gồm những chuyên gia thống kê lọc lõi nhất, họ chỉ cần liếc mắt qua biểu đồ tần số là biết ngay một bộ dữ liệu đã bị cấy ghép nhân tạo vụng về. Việc thuê một dịch vụ chuyên nghiệp chính là thao tác mua một sự đảm bảo khoa học vững chắc, nơi các số liệu được xử lý mượt mà bởi thuật toán thông minh chứ không phải là trò chơi may rủi nguy hiểm của cảm tính con người.
5. Câu Hỏi Thường Gặp (FAQs) Khi Xử Lý Dữ Liệu SPSS
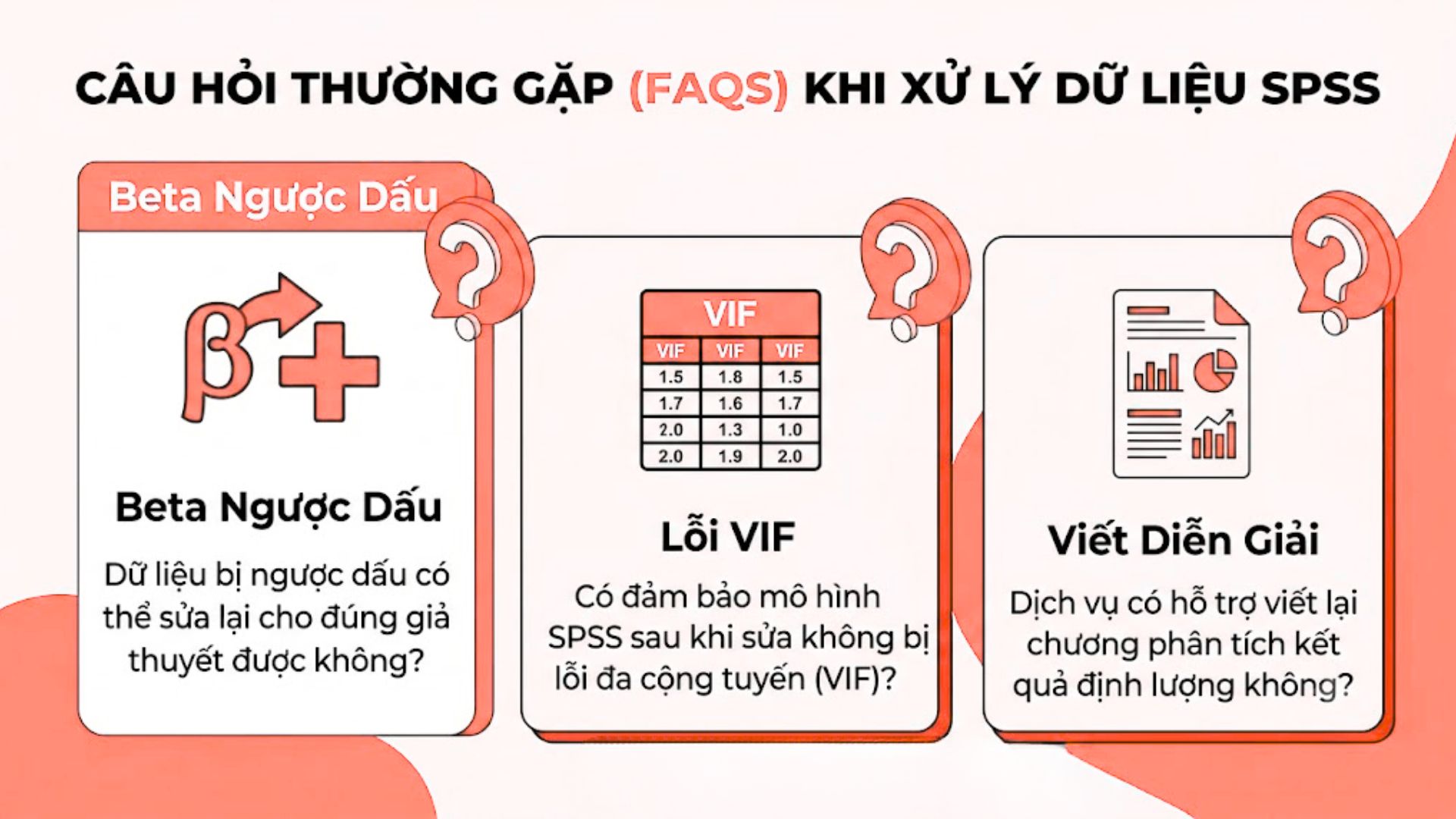
5.1. Dữ liệu bị ngược dấu có thể sửa lại cho đúng giả thuyết được không?
Đội ngũ cam kết 100% có năng lực xoay chuyển tình thế, nắn lại đúng 1 hướng tác động của biến độc lập mà không làm hỏng giá trị của biến khác.
Chắc chắn là được và đây là nghiệp vụ cốt lõi của chúng tôi. Hiện tượng ngược dấu dù là cơn ác mộng cực độ nhưng hoàn toàn nằm trong tầm kiểm soát an toàn của các thuật toán phân tích thành phần chính hiện đại. Thông qua việc tinh chỉnh lại chi tiết ma trận tương quan nội bộ và kiểm soát triệt để các biến số đang gây ra hiệu ứng ức chế ngầm, chuyên gia sẽ khéo léo đưa hệ số hồi quy trở lại đúng quỹ đạo mang dấu âm hoặc dương mà khung lý thuyết của bạn đã kỳ vọng từ ban đầu.
5.2. Có đảm bảo mô hình SPSS sau khi sửa không bị lỗi đa cộng tuyến (VIF)?
Cam kết mọi chỉ số dung sai luôn lớn hơn 0.5 và hệ số phóng đại phương sai VIF luôn duy trì ổn định dưới mức 2.0 an toàn tuyệt đối.
Kiểm soát triệt để đa cộng tuyến là tiêu chuẩn bắt buộc phải có trong mọi quy trình nghiệm thu nội bộ của chúng tôi. Việc xử lý hiện tượng ngược dấu luôn được tiến hành song song đồng bộ với việc kìm hãm đà tăng của hệ số VIF. Khách hàng sẽ nhận được bảng kết quả tóm tắt với cột thống kê cộng tuyến thỏa mãn xuất sắc mọi điều kiện khắt khe nhất, bảo vệ mô hình của bạn khỏi mọi sự hoài nghi gay gắt về sự trùng lặp khái niệm giữa các biến độc lập.
5.3. Dịch vụ có hỗ trợ viết lại chương phân tích kết quả định lượng không?
Triển khai 1 gói giải pháp trọn gói bao gồm phân tích số liệu mới, kết hợp chắp bút diễn giải học thuật hoàn chỉnh cho 1 chương thực nghiệm dài.
Hiểu thấu đáo được sự khó khăn khổng lồ trong việc chuyển ngữ các con số khô khan thành văn bản khoa học mượt mà, chúng tôi cung cấp dịch vụ viết kèm diễn giải chuyên sâu vô cùng tiện ích. Các con số phức tạp trong bảng phân tích phương sai sẽ được chuyển hóa tài tình thành những đoạn văn phân tích sắc sảo, viện dẫn lý thuyết nền tảng chặt chẽ. Cách hành văn tuân thủ đúng chuẩn mực học thuật cao cấp nhất, giúp bạn sở hữu một chương phân tích định lượng vừa chặt chẽ bất khả xâm phạm về toán học, vừa xuất sắc vượt trội về mặt lập luận logic.
—
Nghiên cứu khoa học sử dụng công cụ định lượng thống kê là một hành trình dài đầy rẫy những thách thức cam go đòi hỏi sự kiên nhẫn bền bỉ và một nền tảng kiến thức vô cùng vững chắc. Việc vấp phải những rào cản kỹ thuật như biến quan sát bị gạch bỏ không thương tiếc trong ma trận khám phá, dữ liệu vi phạm nghiêm trọng giả định tương quan hay phương trình hồi quy đưa ra các kết luận ngược chiều là điều không một cá nhân nào mong muốn nhưng lại vô cùng phổ biến trong thực tiễn. Thay vì phải loay hoay chìm trong sự bế tắc hoặc đối mặt với rủi ro đánh mất hoàn toàn tính trung thực của công trình nghiên cứu do tự ý xào nấu số liệu thủ công, sự can thiệp kịp thời của một dịch vụ tối ưu phần mềm phân tích chuyên nghiệp chính là chiếc chìa khóa vạn năng cứu cánh. Với nền tảng thuật toán thống kê minh bạch chuẩn xác và đội ngũ chuyên gia nhiệt huyết tận tâm, chúng tôi tự hào và tự tin đồng hành cùng bạn kiến tạo lại một hệ thống dữ liệu vững chãi hoàn mỹ, đưa dự án nghiên cứu cập bến an toàn vinh quang và bảo vệ thành công tấm bằng tốt nghiệp danh giá một cách xuất sắc nhất.
Viết Thuê 247: Khi các bạn cần, chúng tôi có
-
Website: https://vietthue247.vn/
-
Hotline: 0904514345
-
Email: vietthue247@gmail.com

